coldstart.py¶
Führt die in Abb. gezeigten Schritte Kaltstart bis Rebuild aus. Als Eingabe wird die Datenbank des MPD–Servers verwendet, fehlende Liedtexte werden ergänzt und die Audiodaten für die moodbar und für die Beats-per–Minute–Analyse wird lokalisiert.
Im Anschluss wird die Session aufgebaut und unter $HOME/.cache/libmunin/EasySession.gz gespeichert.
#!/usr/bin/env python
# encoding: utf-8
# Python Stdlib:
import logging
# Moosecat imports:
import moosecat.boot
from moosecat.boot import g
# External imports:
from munin.easy import EasySession
from munin.provider import PlyrLyricsProvider
# Fetch missing lyrics, or load them from disk.
# Also cache missed items for speed reasons.
LYRICS_PROVIDER = PlyrLyricsProvider(cache_failures=True)
# Construct a munin-song from a mpd-song
def make_entry(song):
# Hardcoded, Im sorry:
full_uri = '/mnt/testdata/' + song.uri
# Also return the uri, as unique Identifier.
return song.uri, {
'artist': song.artist,
'album': song.album,
'title': song.title,
'genre': song.genre,
'bpm': full_uri,
'moodbar': full_uri,
'rating': None,
'date': song.date,
'lyrics': LYRICS_PROVIDER.do_process((
song.album_artist or song.artist, song.title
))
}
if __name__ == '__main__':
# Bring up moosecat:
# First connect to the server under 6601,
# then boot the metadata system, afterwards the database.
moosecat.boot.boot_base(verbosity=logging.DEBUG)
g.client.connect(port=6601)
moosecat.boot.boot_metadata()
moosecat.boot.boot_store()
# Fetch the whole database into `entries`:
entries = []
with g.client.store.query('*', queue_only=False) as playlist:
for song in playlist:
entries.append(make_entry(song))
# Instance a new EasySession and fill in the values.
session = EasySession()
# Remember to call a rebuild afterwards:
with session.transaction():
for uri, entry in entries:
try:
print('Processing:', entry['bpm'])
# Remember the song under the uri
session.mapping[session.add(entry)] = uri
except:
# In case something gets wrong: Prettyprint it.
import traceback
traceback.print_exc()
# Save the Session to disk (~/.cache/libmunin/EasySession.gz)
session.save()
# Plot, if desired.
if '--plot' in sys.argv:
session.database.plot()
# Close the connection to MPD, save cached database
moosecat.boot.shutdown_application()
Ausführliches Beispiel¶
Der Vollständigkeit halber soll hier noch ein ausführliches Beispiel gezeigt werden, das auch im Vergleich zum einfachen Beispiel folgende Features zeigt:
- Das Erstellen einer eigenen Session (mittels Session).
- Das Speichern und Laden derselben (mittels Session.load() / Session.save()).
- Das Füttern der Historie (mittels Session.feed_history()).
- Anzeige der abgeleiteten Assoziationsregeln (mittels Session.rule_index).
- Mehrere Möglichkeiten zur Empfehlung (wie Session.recommend_from_heuristic()).
#!/usr/bin/env python
# encoding: utf-8
# complex.py
import sys
from munin.helper import pairup
from munin.session import Session
from munin.distance import GenreTreeDistance, WordlistDistance
from munin.provider import \
ArtistNormalizeProvider, \
GenreTreeProvider, \
WordlistProvider, \
StemProvider
MY_DATABASE = [(
'Devildriver', # Artist
'Before the Hangmans Noose', # Title
'metal' # Genre
), (
'Das Niveau',
'Beim Pissen gemeuchelt',
'folk'
), (
'We Butter the Bread with Butter',
'Extrem',
'metal'
), (
'Lady Gaga',
'Pokerface',
'pop'
)]
def create_session(name):
print('-- No saved session found, loading new.')
session = Session(
name='demo',
mask={
# Each entry goes like this:
'Genre': pairup(
# Pratice: Go lookup what this Providers does.
GenreTreeProvider(),
# Practice: Same for the DistanceFunction.
GenreTreeDistance(),
# This has the highest rating of the three attributes:
8
),
'Title': pairup(
# We can also compose Provider, so that the left one
# gets the input value, and the right one the value
# the left one processed.
# In this case we first split the title in words,
# then we stem each word.
WordlistProvider() | StemProvider(),
WordlistDistance(),
1
),
'Artist': pairup(
# If no Provider (None) is given the value is forwarded as-is.
# Here we just use the default provider, but enable
# compression. Values are saved once and are givean an ID.
# Duplicate items get the same ID always.
# You can trade off memory vs. speed with this.
ArtistNormalizeProvider(compress=True),
# If no DistanceFunctions is given, all values are
# compared with __eq__ - which might give bad results.
None,
1
)
}
)
# As in our first example we fill the session, but we dont insert the full
# database, we leave out the last song:
with session.transaction():
for idx, (artist, title, genre) in enumerate(MY_DATABASE[:3]):
# Notice how we use the uppercase keys like above:
session.mapping[session.add({
'Genre': genre,
'Title': title,
'Artist': artist,
})] = idx
return session
def print_recommendations(session, n=5):
# A generator that yields at max 20 songs.
recom_generator = session.recommend_from_heuristic(number=n)
seed_song = next(recom_generator)
print('Recommendations to #{}:'.format(seed_song.uid))
for munin_song in recom_generator:
print(' normalized values:')
# Let's take
for attribute, normalized_value in munin_song.items():
print(' {:<7s}: {:<20s}'.format(attribute, normalized_value))
original_song = MY_DATABASE[session.mapping[munin_song.uid]]
print(' original values:')
print(' Artist :', original_song[0])
print(' Album :', original_song[1])
print(' Genre :', original_song[2])
print()
if __name__ == '__main__':
print('The database:')
for idx, song in enumerate(MY_DATABASE):
print(' #{} {}'.format(idx, song))
print()
# Perhaps we already had an prior session?
session = Session.from_name('demo') or create_session('demo')
rules = list(session.rule_index)
if rules:
print('Association Rules:')
for left, right, support, rating in rules:
print(' {:>10s} <-> {:<10s} [supp={:>5d}, rating={:.5f}]'.format(
str([song.uid for song in left]),
str([song.uid for song in right]),
support, rating
))
print()
print_recommendations(session)
# Let's add some history.
# Here: First the song 0 (as munin-id) then 2 .. and so on.
for munin_uid in [0, 2, 0, 0, 2]:
session.feed_history(munin_uid)
print('Playcounts:')
for song, count in session.playcounts().items():
print(' #{} was played {}x times'.format(song.uid, count))
# Let's insert a new song that will be in the graph on the next run:
if len(session) != len(MY_DATABASE):
with session.fix_graph():
session.mapping[session.insert({
'Genre': MY_DATABASE[-1][2],
'Title': MY_DATABASE[-1][1],
'Artist': MY_DATABASE[-1][0]
})] = 3
if '--plot' in sys.argv:
session.database.plot()
# Save it under ~/.cache/libmunin/demo
session.save()
Ausgabe nach dem ersten Lauf:
The database:
#0 ('Devildriver', 'Before the Hangmans Noose', 'metal')
#1 ('Das Niveau', 'Beim Pissen gemeuchelt', 'folk')
#2 ('We Butter the Bread with Butter', 'Extrem', 'metal')
#3 ('Lady Gaga', 'Pokerface', 'pop')
-- No saved session found, loading new.
Recommendations to #0:
normalized values:
Artist : (3,)
Genre : ((583,),)
Title : ['Extrem']
original values:
Artist : "We Butter the Bread with Butter"
Album : "Extrem"
Genre : "metal"
Playcounts:
#0 was played 3x times
#2 was played 2x times
Ausgabe nach dem 5ten Lauf:
The database:
#0 ('Devildriver', 'Before the Hangmans Noose', 'metal')
#1 ('Das Niveau', 'Beim Pissen gemeuchelt', 'folk')
#2 ('We Butter the Bread with Butter', 'Extrem', 'metal')
#3 ('Lady Gaga', 'Pokerface', 'pop')
Recommendations to #2:
normalized values:
Artist : (1,)
Genre : ((583,),)
Title : ['the', 'Befor', 'Noos', 'Hangman']
original values:
Artist : "Devildriver"
Album : "Before the Hangmans Noose"
Genre : "metal"
Playcounts:
#0 was played 15x times
#2 was played 10x times
Ausgabe nach dem 10ten Lauf:
The database:
#0 ('Devildriver', 'Before the Hangmans Noose', 'metal')
#1 ('Das Niveau', 'Beim Pissen gemeuchelt', 'folk')
#2 ('We Butter the Bread with Butter', 'Extrem', 'metal')
#3 ('Lady Gaga', 'Pokerface', 'pop')
Association Rules:
[2] <-> [0] [supp=8, rating=0.83951]
Recommendations to #2:
normalized values:
Artist : (1,)
Genre : ((583,),)
Title : ['the', 'Befor', 'Noos', 'Hangman']
original values:
Artist : "Devildriver"
Album : "Before the Hangmans Noose"
Genre : "metal"
Playcounts:
#0 was played 30x times
#2 was played 20x times
Bilder der Demoanwendung¶
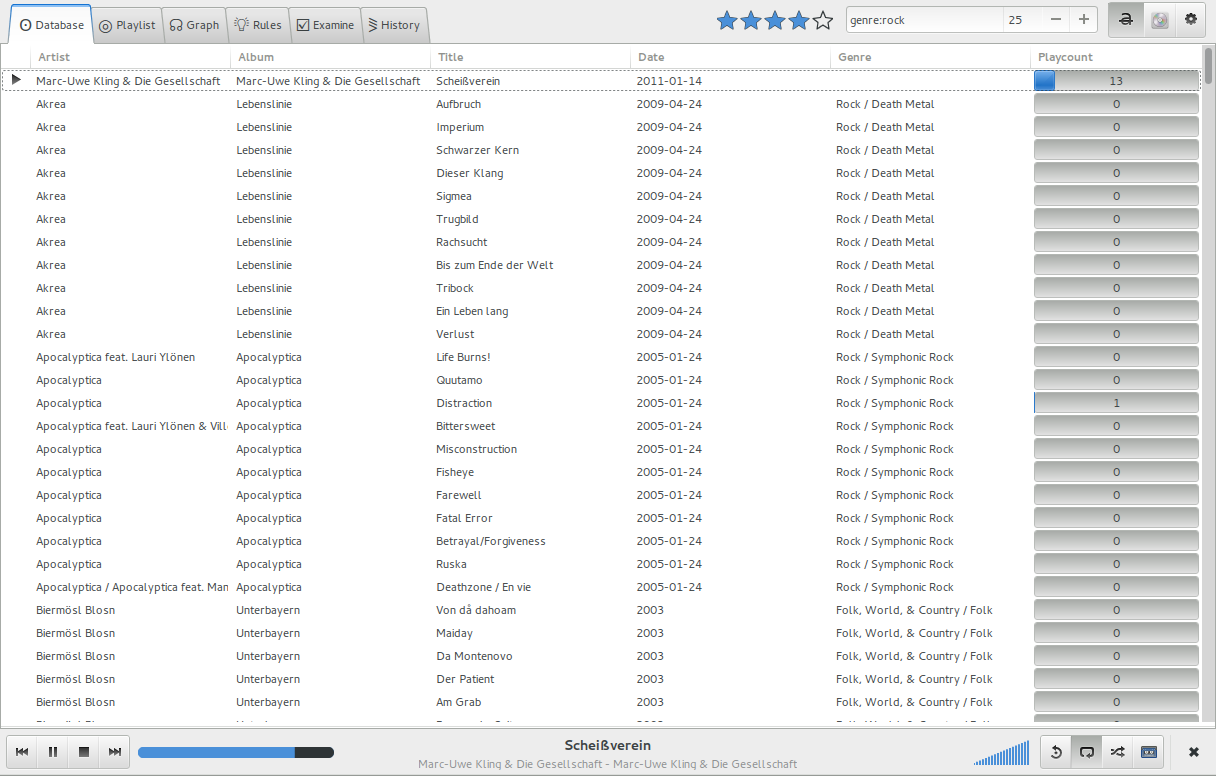
Die Datenbank–Ansicht: Anzeige aller verfügbaren Songs mit folgenden Tags: Artist, Album, Title, Datum, Genre sowie dem Playcount.
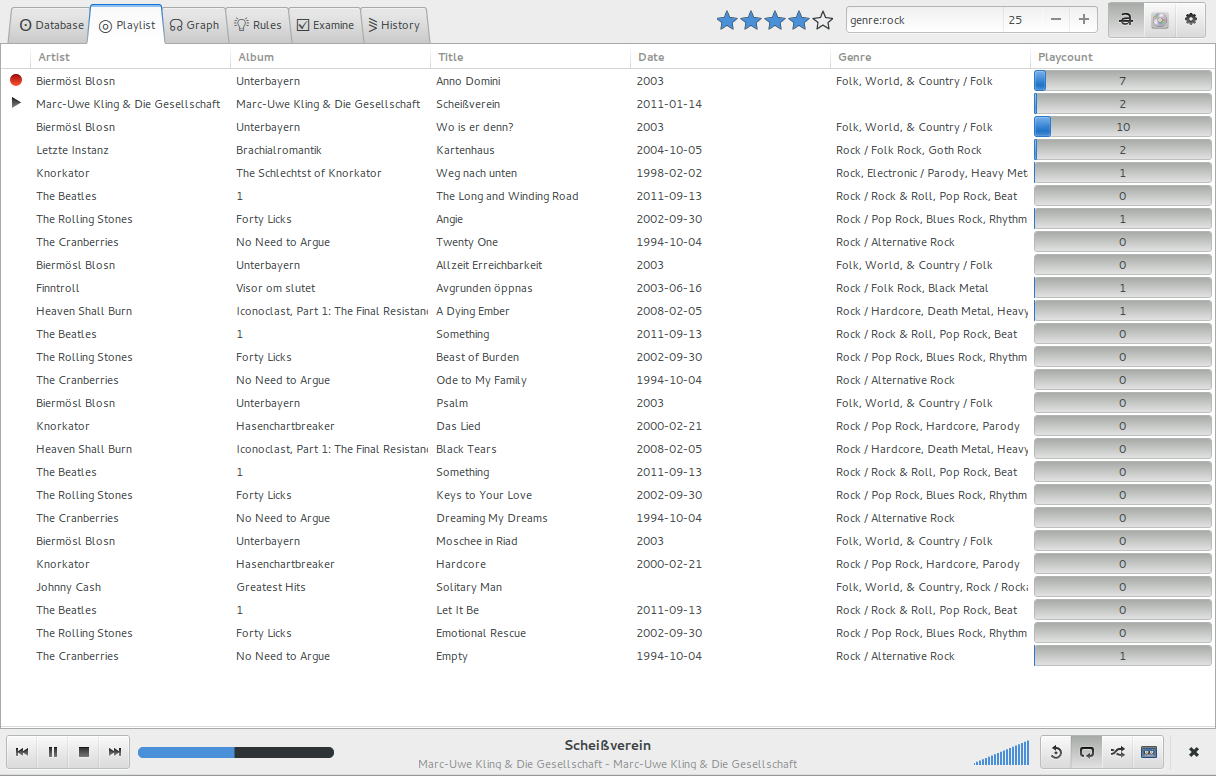
Die aktuelle Playlist, bestehend aus den zuvor erstellten Empfehlungen. Der Seedsong ist durch einen roten Kreis gekennzeichnet.
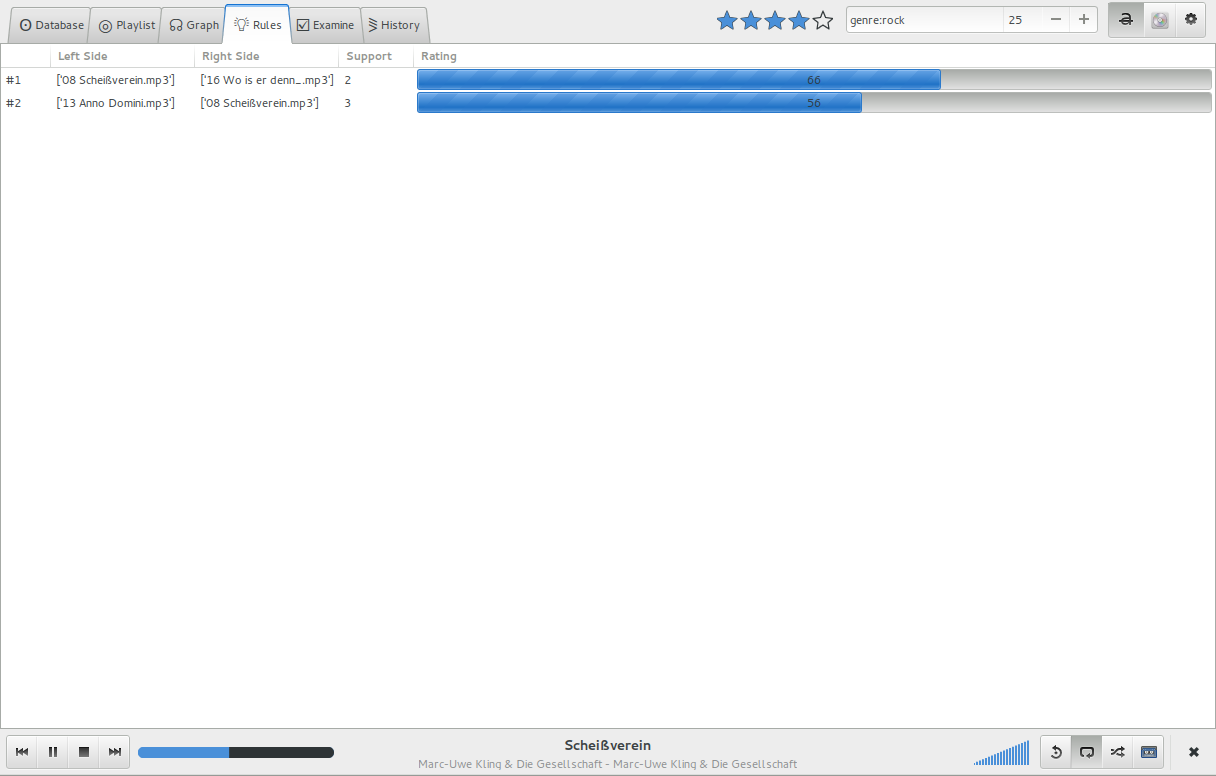
Eine Auflistung der momentan bekannten Regeln. Angezeigt werden: Beide Mengen der Regel, der Supportcount und das Rating.
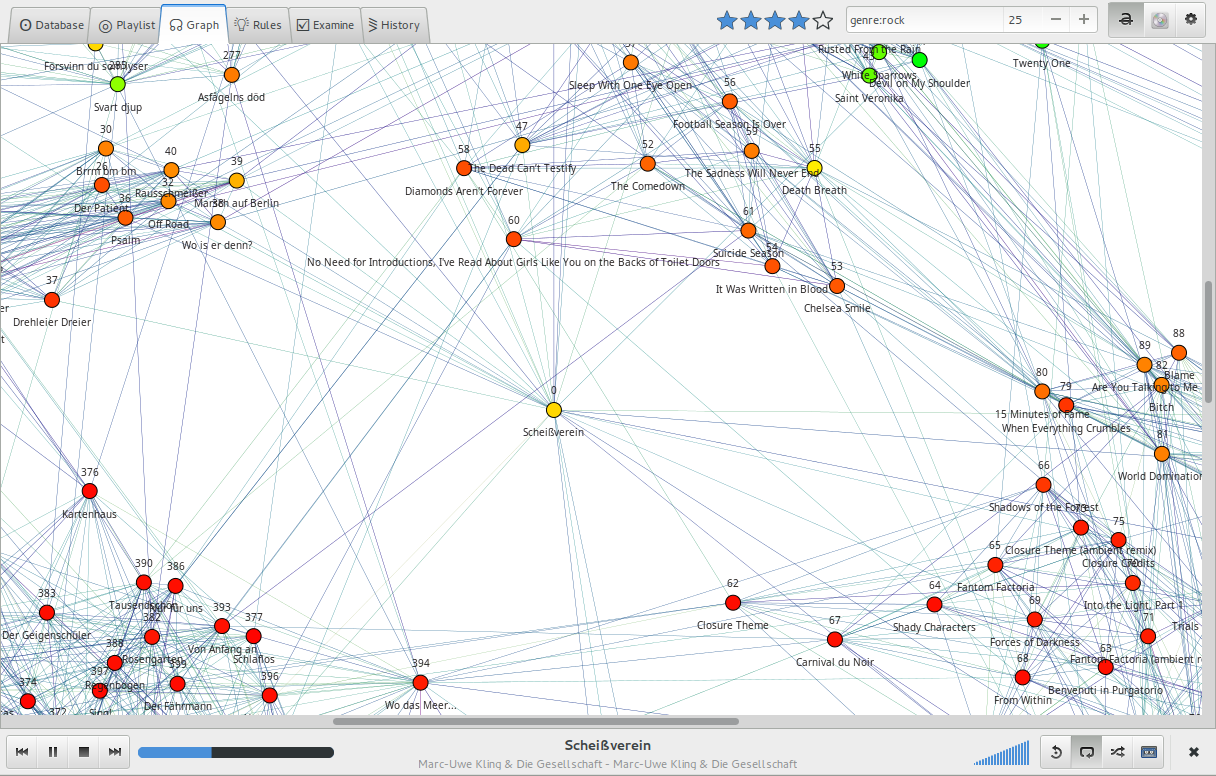
Der Graph der hinter den Empfehlungen steckt, wird hier in 3500x3500px geplottet. Eine Interaktion ist nicht möglich. Über dem Knoten steht die ID des Songs, darunter der Liedtitel. Sonst wie Abb. .
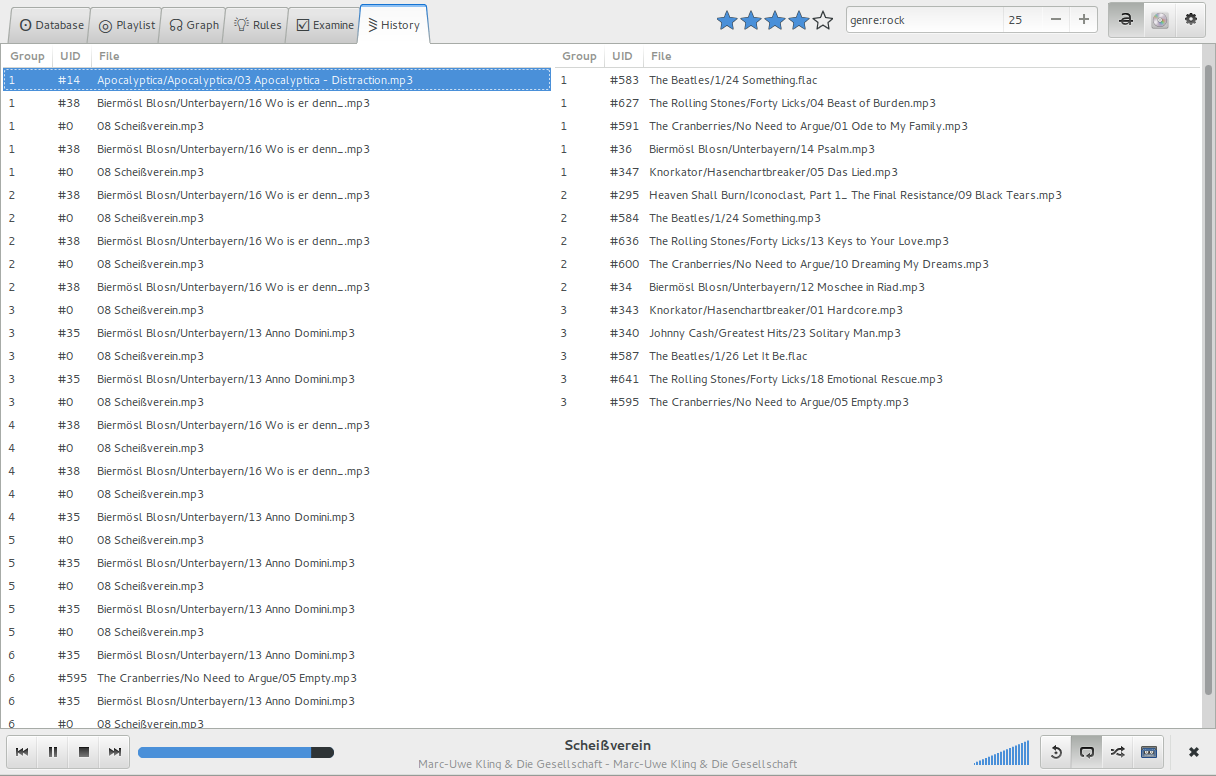
History–Ansicht: die zuletzt gehörten (links) und kürzlich empfohlenen (rechts) Songs werden aufgelistet.
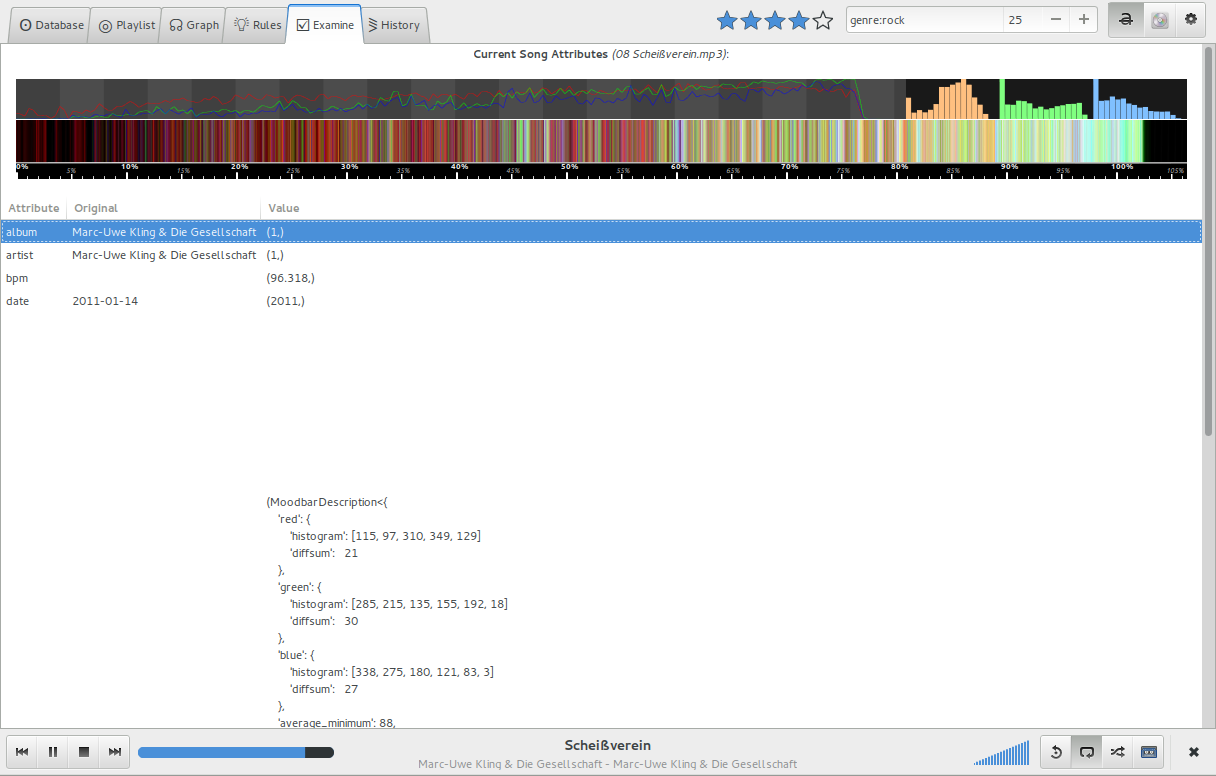
Die ,,Examine”–Ansicht: Die Attribute des aktuellen Songs werden angezeigt. Zudem wird die ,,moodbar”, falls vorhanden, mittels cairo [Link–40] gerendert.