4 Design¶
4.1 Algorithmik¶
Im Folgenden wird ein Überblick über die Algorithmik und die dazugehörigen Datenstrukturen, die im Kern von libmunin stecken, gegeben. Eine genauere Beschreibung wird in der Bachelorarbeit erfolgen. Dieser Überblick soll hauptsächlich dazu dienen einen Einblick in die verwendeten Techniken zu geben.
4.1.1 Grundüberlegungen¶
Die Ähnlichkeit von je einem Song A und B lässt sich durch eine Distanz definieren.
Um die Distanzen zu speichern wird bei vielen Datamining–Projekten eine Distanzmatrix genutzt, also eine quadratische Dreiecksmatrix, in der die Distanzen von jedem Dokument zu jedem anderen gespeichert werden.
Da libmunin auch für eine sehr hohe Anzahl von Songs funktionieren soll, schließt sich die Benutzung einer Distanzmatrix allerdings durch den Aufwand von \(O(n^2)\) aus. Nimmt man an ein Benutzer möchte seine Musiksammlung mit \(40.000\) Liedern importieren, so bräuchten man die folgende Menge an Feldern in der Matrix:
Nimmt man für jedes Feld einen günstig geschätzten Speicherverbrauch von \(4\) Byte an, so bräuchte man allein für die Distanzmatrix hier aufgerundet 3 Gigabyte Hauptspeicher — was selbst für diesen günstig geschätzten Fall unakzeptabel wäre. Auch eine Sparsematrix (vgl. [7]) wäre hier kaum sinnvoll, da in allen Fällen ja trotzdem etwas weniger als die Hälfte aller Felder besetzt sind.
Man muss also versuchen, nur eine bestimmte Anzahl von Distanzen für einen Song zu speichern. Vorzugsweise eine Menge von Songs mit der kleinsten Distanz. Als geeignete Datenstruktur kommt hier ein Graph in Betracht. Die Knoten desselben sind die Songs und die Kanten dazwischen die Distanzen.
Zur besseren optischen Vorstellung ist unter Abb. 4.1 ein Graphen–Plot (erstellt mit igraph [Link–22]) gezeigt.
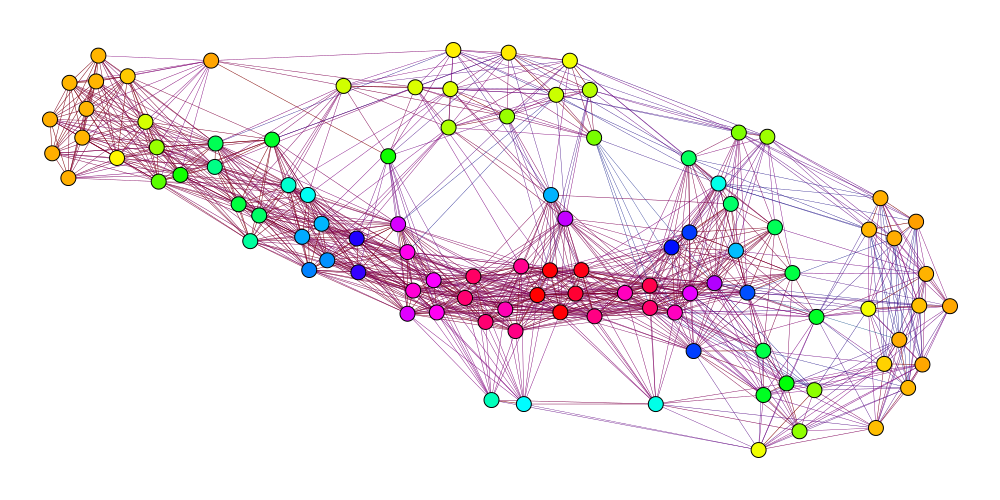
Figure 4.1: Beispielgraph mit 100 Knoten, aus generierten Testdaten. Die Farbe der Knoten zeigt grob die ,,Zentralität" des Knoten an. Pro Knoten wurde ein Integer zwischen 1–100 willkürlich generiert. Diese wurden dann mit einer primitiven Distanzfunktion verglichen. Die Länge der Kanten ist durch das Layout bedingt und deutet nicht auf die Distanz hin.
Jedem Attribut eines Songs ist ein Wert zugeordnet. Um eine sinnvolle Distanzfunktion zu definieren, die zwei Songs miteinander vergleicht, muss man für jedes spezielle Attribut eine eigene Unterdistanzfunktion definieren. Beispielsweise muss für das Genre eine andere Distanzfunktion definiert sein als für den Liedtext.
Um aus den Unterdistanzfunktion eine gemeinsame Distanz zu erhalten, werden die einzelnen Ergebnisse durch einen gewichteten Mittelwert in eine einzelne Distanz zusammengeschmolzen.
4.1.2 Graphenoperationen¶
Um mit unseren Graphen arbeiten zu können, muss man einige Operationen auf ihm definieren:
rebuild: Bevor der Graph benutzt werden kann, muss er natürlich erstmal aufgebaut werden. Der naive Ansatz wäre dabei für jeden Song die Distanzen zu jedem anderen Song zu berechnen. Dies hätte einen Aufwand von \(O(n^2)\) zur Folge. Dies ist aus oben genannten Gründen ebenfalls kaum wünschenswert.
Deshalb kann die rebuild Operation keinen perfekten Graph erzeugen, sondern muss für hinreichend große Datenmengen auf eine Approximation zurückgreifen. Perfekt meint hierbei einen Graphen bei dem jeder Knoten wirklich mit den absolut besten Nachbarn verbunden ist.
Nach dem Aufbau sollte ein ungerichteter Graph dabei herauskommen, in dem idealerweise jeder Knoten vom jedem anderen Knoten erreichbar ist. Es sollten also keine Inseln dabei entstehen. Es gibt keine maximale Anzahl von Nachbarn, die ein Song haben darf, lediglich einen Richtwert.
rebuild_stupid: Wie rebuild, nutzt aber quadratischen Aufwand, indem es jeden Song mit jedem anderen vergleicht. Dies ist für kleine Mengen (\(\le 400\)) von Songs verträglich und für sehr kleine Mengen sogar schneller. Tatsächlich fällt die normale rebuild-Operation auf diese zurück, falls die Menge an Songs \(\le 200\) ist.
Hauptsächlich für Debugging–Zwecke, um Fehler beim herkömmlichen rebuild aufzudecken.
add: Füge einen einzelnen Song zu dem Graphen hinzu, verbinde ihn aber noch nicht. Dies ist die bevorzugte Operation um viele Songs dem Graphen hinzuzufügen, beispielsweise beim Kaltstart, da das Verbinden später in einem rebuild-Schritt erledigt werden kann.
insert: Füge einen einzelnen Song zu dem Graphen hinzu und verbinde ihn. Suche dazu erst eine passende Stelle in der er sinnvoll eingepasst werden kann.
remove: Entferne einen einzelnen Song aus dem Graphen und versuche das entstandene Loch zu flicken, indem die Nachbarn des entfernten Songs untereinander verkuppelt werden.
modify: Manchmal ist es nötig das Attribut eines einzelnen Songs, wie beispielsweise das stark vom Benutzer abhängige Rating, zu ändern. Dabei wird der Song erst mittels remove entfernt, die Attribute werden angepasst und er wird mittels insert wieder eingefügt. Diese Operation ist dadurch relativ teuer und sollte mit Bedacht eingesetzt werden.
fixing: Durch das Löschen und Hinzufügen von Songs können Einbahnstraßen im Graphen entstehen. Durch den nachgelagerten fixing–Schritt werden diese, nach bestimmten Regeln, entweder entfernt oder in bidirektionale Verbindungen umgebaut. Nach jedem insert, remove und rebuild sollte dieser Schritt erfolgen.
4.1.3 Ausstellen von Empfehlungen¶
Das Ausstellen von Empfehlungen wird durch das Traversieren des Graphen mittels einer Breitensuche erledigt. Dabei wird der Ursprung durch einen sogenannten Seedsong bestimmt. Anschaulich wäre der Seedsong bei einer Anfrage wie ,,10 ähnliche Songs zu The Beatles – Yellow Submarine " eben ,,Yellow Submarine".
Aus der funktionalen Programmierung wurde dabei das Konzept der Infinite Iterators übernommen: Anstatt einer bestimmten Anzahl von Empfehlungen als Liste, wird ein Versprechen herausgegeben, die Empfehlungen genau dann zu berechnen, wenn sie gebraucht werden (Lazy Evaluation). Dadurch ist auch die Zahl der zu gebenden Empfehlungen variabel. Dies ist sehr nützlich beim Erstellen einer intelligenten, fortlaufenden Playlist.
Es können auch mehrere Seedsongs verwendet werden, dann werden die einzelnen Iteratoren im Reißschlußverfahren verwebt.
Basierend auf dieser Idee ist es möglich, bestimmte Strategien zu implementieren, die beispielsweise Songs mit der höchsten Abspielanzahl (Playcount), dem besten Rating oder einem bestimmten Attribut wie ,,genre=rock" als Seedsongs auswählen.
4.1.4 Filtern von Empfehlungen¶
Oft ist es nötig, die gegebenen Empfehlungen noch zusätzlich zu filtern. Das hat den simplen Grund, dass im Graphen die meisten Alben einzelne Cluster bilden. Die Lieder auf einem Album sind meist unter sich sehr ähnlich. Da man aber vermeiden möchte, dass zu einem Seedsong ein Lied vom selben Album oder gar selben Künstler empfohlen wird, müssen diese beim Iterieren über den Graphen ausgesiebt werden.
Dazu werden die zuletzt gegebenen Empfehlungen betrachtet. Ist zum Beispiel in den letzten fünf Empfehlungen der gleiche Künstler bereits vorhanden, so wird die Empfehlung ausgesiebt.
4.1.5 Lernen durch die Historie¶
Wie bereits erwähnt, soll libmunin Mechanismen bieten um sowohl explizit als auch implizit vom Nutzer zu lernen. Das implizite Lernen erfolgt dabei durch Assoziationsregeln, die aus der Aufzeichnung des Gehörten (der Historie) abgeleitet werden.
Nur eine bestimmte Anzahl von Regeln wird gespeichert. Zuviele Regeln würden historische Altlasten immer weiter mitschleppen und der aktuelle Geschmack des Benutzers würde nicht widergespiegelt werden. Beispielsweise kann man hier einen Hörer nennen der libmunin zwei Jahre lang nutzt und anfangs viel elektronische Ambient–Musik hört, in letzter Zeit aber auf Klassik umgesattelt hat. Nach einiger Zeit sollten also keine Empfehlungen zu elektronischer Musik mehr kommen.
4.2 Integration von libmunin in die Umwelt¶
4.2.1 Allgemeiner Ablauf¶
Eine gut definierte Datenstruktur nützt nichts wenn man nicht weiß wie die Daten, die aus der Umwelt hereinkommen, aussehen. Diese müssen schließlich erstmal in die Form eines Graphen gebracht werden, bevor man Empfehlungen aussprechen kann. Dieser Prozess (siehe Abb. 4.2) beinhaltet vier Schritte:
- Kaltstart: Im Kaltstart müssen mittels Information–Retrieval–Techniken fehlende Daten, wie beispielsweise die Liedtexte oder die die Audiodaten, aus lokalen oder entfernten Quellen beschafft werden. Dies ist Aufgabe des Nutzers. Libmunin bietet hier nur Hilfsfunktionen an. Der Kaltstart ist nur bei der ersten Benutzung einer Musikdatenbank nötig, da die Daten zwischengespeichert werden können.
- Analyse: Bei der Analyse werden die nun vorhandenen Daten untersucht und durch sogenannte Provider normalisiert. Die Normalisierung ist nötig, um im nächsten Schritt eine einfache und effiziente Vergleichbarkeit der Daten zu gewährleisten.
- Rebuild: Dies entspricht der rebuild–Operation. In diesem Schritt werden die normalisierten Daten untereinander mittels einer passenden Distanzfunktion untersucht. Unter Zuhilfenahme, der dabei entstehenden Distanz wird der Graph aufgebaut.
- Einsatz: Durch Traversierung des Graphen können jetzt Ergebnisse abgeleitet werden.

Figure 4.2: Allgemeiner Benutzungsprozess von libmunin, in vier Stufen aufgeteilt.
4.2.2 Die Umgebung¶
In Abb. 4.3 ist eine Übersicht gegeben, in welcher Umgebung libmunin eingesetzt wird. Eine Frage die sich dabei stellt ist: Wie stellen die Nutzer der Bibliothek ihre Musikdatenbank bereit? Und wie geben sie diese an libmunin weiter?
Dazu bedarf es einer weiteren Eingabe vom Nutzer: Einer Beschreibung wie die Lieder in seiner Musikdatenbank aufgebaut sind. Also welche Tags sie enthalten und wie mit diesen Daten verfahren werden soll.
Da diese Daten sehr unterschiedlich geartet sind, muss libmunin sehr generisch aufgebaut sein. Der Ansatz ist dabei, zusätzlich vom Nutzer eine Maske zu verlangen, die beschreibt welche möglichen Tags (oder Attribute) ein einzelner Song besitzt. Für jedes Attribut kann dann, nach Baukastenprinzip, ein Provider, eine Distanzfunktion und eine Gewichtung ausgewählt werden. Letztere beschreibt, wie wichtig dieses Attribut aus Sicht des Nutzers in Bezug auf die Ähnlichkeit ist. Der Provider normalisiert die Werte von einem Attribut auf bestimmte Art und Weise, während sich die Distanzfunktion um das Vergleichen der normalisierten Werte nach bestimmten, je nach Art des Attributs spezialisierten Weise, kümmert.
Nachdem das Format, in Form der Maske, geklärt ist, kann der Nutzer jeden Song mittels der add-Operation hinzufügen und im Anschluss eine rebuild-Operation triggern.

Figure 4.3: Integration von libmunin in seine Umwelt. Die Grafik ist in drei unterschiedliche, durch Striche getrennte, Ebenen aufgeteilt: Unten der Nutzerbereich (Entwickler oder Endanwender die libmunin nutzen), in der Mitte die Entwickler von libmunin und oben die externen Ressourcen auf die libmunin zugreifen kann.
Nun ist klar wie die interne Datenstruktur und die externen Daten aussehen. Der nächste Schritt besteht darin, sich Gedanken über den Layer zu machen, welcher zwischen beiden vermittelt.
Tatsächlich besteht ein großer Teil von libmunin aus diesem Layer, der Daten aus der Umwelt nimmt und in die interne Graphendarstellung transferiert.
In Abb. 4.4 findet sich eine zusammenfassende Darstellung von libmunin als ,,Whitebox". Also als Box mit allen Ein- und Ausgängen, sowie der groben Verarbeitung dazwischen.

Figure 4.4: Betrachtung von libmunin als ,,Whitebox”. Alle Eingaben (links) und Ausgaben (rechts) in einem Bild. In der Box selbst ist die grobe Verarbeitung der Daten skizziert.
4.3 Entwurf der Software¶
Nachdem nun geklärt ist aus welchen Komponenten unsere Software besteht, kann man sich Gedanken darüber machen, wie diese einzelnen Teile konkret aussehen. Im Folgenden werden die ,,Hauptakteure" der Software vorgestellt.
4.3.1 Übersicht¶
Unter Abb. 4.5 findet sich eine grobe Übersicht der wichtigsten Klassen. Libmunin's Entwurf basiert, dort wo es Sinn macht, auf Prinzipien der Objektorientierten Programmierung. Einige Teile der Funktionalität, wie die Graphentraversierung, sind allerdings prozedural implementiert.

Figure 4.5: Jeder Node ist eine Klasse in den jeweiligen Teilbereichen der Software. Provider und DistanceFunction Unterklassen nur beispielhaft gezeigt.
4.3.2 Grobe Unterteilung¶
Im Folgenden werden die einzelnen Regionen der Software betrachtet. Danach werden die einzelnen Komponenten dieser Regionen näher beleuchtet. Grob ist die Software in fünf unterschiedliche Regionen aufgeteilt. Im Folgenden werden diese Regionen vorgestellt:
API: Die API ist die Schnittstelle zum Benutzer hin. Der Nutzer kann mittels einer Session auf alle Funktionen von libmunin zugreifen. Dazu muss er beim Instantiieren derselben eine Maske angeben, die die Musikdatenbank beschreibt. Alternativ kann die EasySession genutzt werden. Diese bietet eine vordefinierte Maske, die für viele Anwendungsfälle ausreichend ist.
Provider–Pool: Implementiert eine große Menge vordefinierter Provider, um die die gängigsten Eingabedaten (wie Künstler, Album, Liedtexte, Genre, ...) abzudecken. Manche Provider dienen auch zum Information Retrieval und ziehen beispielsweise Liedtexte aus dem Internet. Eine volle Liste von verfügbaren Providern wird unter Kapitel 5.4 gegeben.
DistanceFunction–Pool: Implementiert eine Menge vordefinierter Distanzfunktionen, welche die Werte der obigen Provider vergleichen. Dabei kommen zwar viele Provider und Distanzfunktion als Paare daher (wie beispielsweise der GenreTree–Provider und die GenreTree–Distanzfunktion), was aber keine Notwendigkeit darstellt. Verschiedene Provider können beispielsweise dieselbe Distanzfunktion nutzen.
Eine volle Liste von verfügbaren Distanzfunktionen wird unter Kapitel 5.5 gegeben.
Nutzer der Bibliothek können eigene Provider oder DistanceFunctions implementieren, indem sie von den jeweiligen Oberklassen ableiten.
Songverwaltung: Hier passiert alles was mit dem Speichern und Vergleichen einzelner Songs zu tun hat. Dies umfasst das Speichern der Songs in der Database, sowie dem Verwalten der benachbarten Songs für jeden Song mit den dazugehörigen Distance–Instanzen.
Die Graphendatenstruktur entsteht durch die Verknüpfungen der Songs untereinander und bildet keine eigenständige Klasse.
Regeln und Historie: Dieser Teil von libmunin ist für das Aufzeichnen des Benutzerverhaltens und dem Ableiten von Assoziationsregeln daraus zuständig.
4.3.3 Einzelne Komponenten¶
Da UML–Diagramme sich oft in unwichtige Details und akribische Methodenauflistungen versteigen, wird im Folgenden textuell eine Auflistung aller Klassen und ihren Aufgaben gegeben. Nur in Einzelfällen werden Methodennamen gekennzeichnet.
Session: Die Session ist das zentrale Objekt für den Nutzer der Bibliothek. Es bietet über Proxymethoden Zugriff auf alle Funktionalitäten von libmunin und kann persistent abgespeichert werden. Dies wird durch das Python–Modul pickle realisiert. Es speichert rekursiv alle Member einer Session–Instanz in einem Python-spezifischen Binärformat. Voraussetzung hierfür ist, dass alle Objekte direkt oder indirekt an die Session–Instanz gebunden sind.
Der Speicherort entspricht dem XDG Standard [Link–23], daher wird jede Session als gzip gepackt unter $HOME/.cache/libmunin/<name>.gz gespeichert. Der <name> lässt sich der Session beim Instanzieren übergeben.
Die weitere Hauptzuständigkeit einer Session ist die Implementierung der Empfehlungsstrategien welche den Graphen traversieren.
Song: Speichert für jedes Attribut einen Wert, oder einen leeren Wert falls das Attribut nicht gesetzt wurde. Dies ähnelt einer Hashtabelle, allerdings werden nur die Werte gespeichert, die Schlüssel der Hashtabelle werden in der Maske gespeichert und im Song nur referenziert. Der Grund dieser Optimierung liegt im verminderten Speicherverbrauch.
Eine weitere Kompetenz dieser Klasse ist das Verwalten der Distanzen zu seinen Nachbarsongs. Er muss Methoden bieten um eine Distanz zu einem Nachbarn hinzuzufügen oder zu entfernen, Methoden um über alle Nachbarn zu iterieren oder die Distanz zu einen bestimmten Nachbarn abzufragen. Hinzukommt eine disconnect()–Methode um den Song zu entfernen ohne dabei ein ,,Loch" zu hinterlassen.
Wie bereits erwähnt, gibt es keine eigene Graph–Klasse. Der Graph an sich wird durch die Verknüpfung der einzelnen Songs in der Database gebildet. Jede Song–Instanz bildet dabei einen Knoten.
Da eine Veränderung von Attributen im Song auch eine Veränderung im Graphen zur Folge haben kann, sind Instanzen der Song–Klasse Immutable, sprich nach ihrer Erstellung kann ihr Inhalt nicht mehr verändern werden. Ist dies trotzdem vonnöten, kann die modify-Operation eingesetzt werden. Ein praktischer Einsatzgrund wäre beispielsweise das Ändern des Ratings eines Songs. Es sollte allerdings erwähnt werden, dass die modify–Operation relativ aufwendig ist. Schließlich muss der Song entfernt und neu eingefügt werden.
Mask: Speichert, ähnlicher einer Hashtabelle, die Namen der einzelnen Attribut als Schlüssel. Als Wert wird ein Tripel aus jeweils einem Provider, einer DistanceFunction und einer Gewichtung assoziiert. Da dies bereits in Kapitel 4.2.2 erklärt wurde, wird hier ein kurzes, praktisches Python–Beispiel gezeigt:
m = Mask({ # Mask erwartet als Übergabe eine Hashtabelle
'genre': pairup( # Verknüpfe Distanzfunktion mit Provider
GenreTreeProvider(), # Instantiiere einen Provider
GenreTreeAvgLinkDistance(), # Instantiiere eine Distanzfunktion
4.0 # Gewichtung des Attributes (beliebiger Wert)
), # [...] Weitere Attribute
})
session = Session(m) # Instantiiere eine Session mit dieser Maske
Wie man sieht wird als Schlüssel der Name des Attributes festgelegt und als Wert ein Tupel aus einer Provider–Instanz, aus einer DistanceFunction–Instanz und der Gewichtung dieses Attributes als float.
Wird statt einem Provider- oder einer DistanceFunction–Instanz, der leere Wert None übergeben, so wird ein DefaultProvider (reicht die Werte unverändert weiter), beziehungsweise eine DefaultDistanceFunction (vergleicht Werte mit dem Standard ,,==–Operator") ersetzt.
Ein umfangreicheres Beispiel findet sich im Kapitel Ausführliches Beispiel.
EasySession: Wie die normale Session, bietet aber eine bereits fertig konfigurierte Maske an, die für viele Anwendungsfälle ausreicht. In Tabelle 4.6 ist eine Auflistung gegeben, wie diese im Detail konfiguriert ist. Die einzelnen Provider werden später noch im Detail erklärt.
| Attribut | Provider | Distanzfunktion | Eingabe | Weight | Kompression? |
|---|---|---|---|---|---|
| artist | ArtistNormalize | Default | Künstler | \(1\times\) | \(\checkmark\) |
| album | AlbumNormalize | Default | Albumtitel | \(1\times\) | \(\checkmark\) |
| title | TitleNormalize | Default | Tracktitel | \(2\times\) | |
| date | Date | Date | Datums–String | \(4\times\) | |
| bpm | BPMCached | BPM | Audiofile–Pfad | \(6\times\) | |
| lyrics | Keywords | Keywords | Songtext | \(6\times\) | |
| rating | Default | Rating | Integer (\(\in [0, 5]\)) | \(4\times\) | |
| genre | GenreTree | GenreTreeAvg | Genre–String | \(8\times\) | \(\checkmark\) |
| moodbar | MoodbarAudioFile | Moodbar | Audiofile–Pfad | \(9\times\) |
Figure 4.6: Default–Konfiguration der ,,EasySession”.
Distance: Wie die Song–Klasse, speichert aber statt den Werten von bestimmten Attributen die Distanz zwischen zwei Attributen. Zusätzlich wird die gewichtete Gesamtdistanz gespeichert. Beispielhaft ist das in Tabelle 4.7 dargestellt.
| Attribut | Unterdistanzen |
|---|---|
| date | 0.9 |
| genre | 0.05 |
| lyrics | 1.0 (Fehlender Wert, Berechnung war nicht möglich) |
| Gewichtete Distanz | \(\frac{4\times0.9 + 8\times0.05 + 6\times1.0}{4 + 8 + 6} = 0.\overline{5}\) |
Figure 4.7: Anschauliche Darstellung der Daten die in einer ,,Distance”–Instanz gespeichert werden. Im Beispiel mit einer Maske die nur drei Attribute hat: date, genre und lyrics. Die Gewichtungen wurden von der ,,EasySession” übernommen.
Manchmal kann es passieren, dass Distanzen nicht berechnet werden können. Als Beispiel ist der Vergleich zweier Lieder anhand den Liedtexten zu nennen. Wenn nur einer davon nicht gefunden werden konnte, muss das Attribut in der Distance leer bleiben. In diesem Fall wird eine Unterdistanz von 1.0 als ,,Strafwert" angenommen.
Der Grund warum man nicht nur die gewichtete Gesamtdistanz abspeichert, sondern auch alle Unterdistanzen, liegt darin, dass es möglich sein soll Empfehlungen zu erklären. Durch das Vorhandensein der Unterdistanzen kann man später feststellen, welches Attribut am stärksten in die Empfehlung mit eingespielt hat. Zudem wird es dadurch technisch möglich, die Gewichtungen in der Maske zur Laufzeit zu ändern. Statt jede Distanz neu zu berechnen, müssen lediglich die einzelnen Distance–Instanzen neu gewichtet werden.
Database: Die Database Klasse ist eine logische Abtrennung der Session, um eine einzige, allmächtige ,,Superklasse" zu verhindern.
Sie hat folgende Aufgaben:
- Implementierung der einzelnen, oben besprochenen Graphenoperationen.
- Zu diesem Zweck hält sie eine Liste von Songs.
- UID–Vergabe für jeden Song.
- Verwaltung der Playcounts, also wie oft jeder Song gespielt wurde.
- Verwaltung der ListenHistory.
- Finden von Songs mit bestimmten Attributen.
History: Oberklasse für RecommendationHistory und ListenHistory. Implementiert die gemeinsame Funktionalität, Songs die zeitlich hintereinander zur History hinzugefügt werden, in Gruppen einzuteilen. Gruppen beinhalten maximal eine bestimmte Anzahl von Songs. Ist eine Gruppe voll, so wird eine neue angefangen. Vergeht aber eine zu lange Zeit seit dem letzten Hinzufügen wird ebenfalls eine neue Gruppe begonnen. Jede abgeschlossene Gruppe wird in der History abgespeichert.
Das Ziel der zeitlichen Gruppierung ist eine Abbildung des Nutzerverhaltens. Die Annahme ist hierbei, dass große zeitliche Lücken zwischen zwei Liedern auf wenig zusammenhängende Songs hindeuten. Zudem bilden die einzelnen Gruppen eine Art ,,Warenkorb", der dann bei der Ableitung von Regeln genutzt werden kann.
RecommendationHistory: Implementiert den unter Kapitel 4.1.4 erwähnten Mechanismus zum Filtern von Empfehlungen.
ListenHistory: Unterklasse von History. Speichert die chronologische Reihenfolge von gehörten Songs. Oft werden vom Endnutzer viele Lieder einfach übersprungen. Diese wenig repräsentativen Lieder sollten nicht zur ListenHistory hinzugefügt werden. Der Nutzer der Bibliothek sollte daher darauf achten, dass nur Lieder hinzugefügt werden, die auch zu einem gewissen Anteil auch angehört wurden.
Insgesamt wird immer nur eine bestimmte Anzahl von Songs in der ListenHistory gespeichert. Dies soll besagte historische Altlasten vermeiden. Momentan ist die Grenze auf 1000 Songs gesetzt.
RuleGenerator: Analysiert die Gruppen innerhalb einer History und leitet daraus mittels einer Warenkorbanalyse Assoziationsregeln ab. Diese werden danach im RuleIndex gespeichert.
RuleIndex: Speichert und indiziert die vom RuleGenerator erzeugten Assoziationsregeln. Die Regeln werden beim Traversieren des Graphen genutzt, um zusätzliche Seedsongs auszuwählen. Daher muss es möglich sein Abfragen wie ,,Gib mir alle Regeln die Song X betreffen" effizient abzusetzen.
Zudem ,,vergisst" der Index Regeln, die Songs betreffen, die nicht mehr in der ListenHistory vorhanden sind.
Provider: Die Oberklasse von der jeder konkreter Provider ableitet: Jeder Provider bietet eine do_process()–Methode die von den Unterklassen überschrieben wird. Zudem bieten viele Provider als ,,Komfort" eine do_reverse()–Methode um für Debuggingzwecke den Originalwert vor der Verarbeitung durch den Provider anzuzeigen.
Provider können, mittels eines speziellen Providers, zu einer Kette zusammengeschaltet werden. Siehe dazu auch: Composite unter Kapitel 5.4.
Oft kommt es vor, dass die Eingabe für einen Provider viele Dupletten enthält. Beispielsweise wird derselbe Künstler–String für viele Songs eingepflegt. Diese redundant zu speichern wäre bei großen Sammlungen unpraktikabel. Daher bietet jeder Provider die Möglichkeit einer primitiven Kompression. Statt den Wert abzuspeichern wird eine bidirektionale Hashtabelle mit den Werten als Schlüssel und einer Integer–ID auf der Gegenseite gehalten. Dadurch wird jeder Wert nur einmal gespeichert und statt dem eigentlichen Wert wird eine ID herausgegeben.
DistanceFuntion: Die Oberklasse von der jede konkrete DistanceFunction ableitet: Jede Distanzfunktion bietet eine do_compute()–Methode, die von den Unterklassen überschrieben wird.
Um die bei den Providern mögliche Kompression wieder rückgängig zu machen, muss die Distanzfunktion den Provider für dieses Attribut kennen. Denn nur dieser kann die Integer–ID wieder auflösen.