5 Implementierung¶
5.1 Anwendungsbeispiel¶
Beispiele sind oft ein guter Weg, um ein Gefühl für eine Bibliothek zu bekommen. Das folgende minimale, in Python gechriebene Beispiel liest Songs aus einer Pseudodatenbank und erstellt für den ersten Song zwei Empfehlungen:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | from munin.easy import EasySession
MY_DATABASE = [
# Artist: Album: Title: Genre:
('Akrea' , 'Lebenslinie' , 'Trugbild' , 'death metal'),
('Vogelfrey' , 'Wiegenfest' , 'Heldentod' , 'folk metal'),
('Letzte Instanz' , 'Götter auf Abruf' , 'Salve te' , 'folk rock'),
('Debauchery' , 'Continue to Kill' , 'Apostle of War' , 'brutal death')
]
session = EasySession()
with session.transaction():
for idx, (artist, album, title, genre) in enumerate(MY_DATABASE):
session.mapping[session.add({
'artist': artist,
'album': album,
'title': title,
'genre': genre
})] = idx
for munin_song in session.recommend_from_seed(0, 2):
print(MY_DATABASE[munin_song.uid])
|
Ist libmunin korrekt installiert 1, so lässt sich dieses Skript als minimal.py ablegen und ausführen:
$ python minimal.py
('Debauchery' , 'Continue to Kill' , 'Apostle of War' , 'brutal death')
('Vogelfrey' , 'Wiegenfest' , 'Heldentod' , 'folk metal'),
5.1.1 Kurze Erläuterung des Beispiels¶
Zeile 1: Der Einstiegspunkt von libmunin's API ist immer eine Session. Da die Konfiguration (Auswahl von Provider, Distanzfunktionen und Gewichtung) einer solchen recht anstrengend werden kann, greifen wir auf eine Session mit vorgefertigter Maske zurück — die sogenannte EasySession.
Zeile 3: Hier erstellen wir uns eine Pseudodatenbank (als Python–Liste) aus vier Liedern mit vier einzelnen Attributen (als Quadrupel) jeweils.
Zeile 10: Hier wird die oben erwähnte EasySession instanziert. Sie dient uns jetzt als Sitzung — alle relevanten Methoden von libmunin können auf der Session aufgerufen werden.
Zeile 11: Beim initialen Importieren der Datenbank werden alle Songs über die add–Operation hinzugefügt. Da add noch keine Verbindungen zwischen den einzelnen Songs herstellt, stellen wir mit dieser Zeile sicher, dass nach dem Importieren ein rebuild ausgeführt wird (implizit in Zeile 19, nach dem Verlassen des vorherigen ,,Blocks").
Zeile 13: Wir iterieren (Zeile 12) über alle Songs in unserer Pseudodatenbank und fügen diese der Session hinzu (über die add–Operation). Zu beachten ist dabei: Es wird eine Hashtabelle übergeben in der bestimmte Schlüssel (wie artist) von der EasySession vorgegeben sind. Erstellt man eine eigene Session, kann man diese nach Belieben konfigurieren.
Ein Problem, dass man bei der Benutzung der Bibliothek hat ist: libmunin und der Nutzer halten zwei verschiedene Datenbanken im Speicher. Der Benutzer verwaltet die Originaldaten mit denen er arbeitet, während libmunin nur normalisierte Daten speichert. Das Problem dabei: Wie soll der Benutzer wissen, welche Empfehlung zu welchem Song in seinen Originaldaten gehört?
Dazu ist eine Abbildung erforderlich, welche die ID, die add() zurückgibt, auf den Index innerhalb von MY_DATABASE abbildet. Diese Abbildung ist im Beispiel session.mapping. Sie erlaubt eine bidirektionales Auflösen der ID von libmunin zum Index in MY_DATABASE, und umgekehrt.
Anmerkung: Zugegeben, dieses Beispiel ist hier etwas konstruiert. Später hat man meist keinen Index in einer Pseudodatenbank, sondern beispielsweise einen Dateipfad als UID.
Zeile 21: In dieser Zeile geben wir die ersten Empfehlungen aus. Wir lassen uns von der EasySession über die Methode recommend_from_seed zwei Empfehlungen zum ersten Song, der über add hinzugefügt wurde, geben. Die Empfehlung selbst wird als Song Objekt ausgegeben. Dieses hat unter anderen eine ID gespeichert, mit der wir die ursprünglichen Daten finden können.
Dieses und weitere Beispiele finden sich auf der API-Dokumentation [Link–24] im Web.
5.1.2 Kurze Erläuterung der Ausgabe¶
Die Ausgabe ist, bei näherer Betrachtung, nicht weiter überraschend: Da sich nur das Genre effektiv vergleichen lässt und wir uns von dem ersten Song ,,Trugbild" zwei Empfehlungen geben ließen, werden die zwei Songs mit dem ähnlichsten Genre ausgegeben.
In Abb. 5.1 ist dies nochmal zu sehen: Der Seedsong (ID 0) ist direkt mit den Songs 1 (Vogelfrey) und 3 (Debauchery) benachbart. Da die beiden Genres folk rock und death metal keine gemeinsame Schnittmenge haben, ist dieser auch kein Nachbar. Verbindungen zwischen zwei Knoten, werden nur dann hergestellt, wenn die Distanz \(< 1.0\) ist.
Ein komplizierteres Beispiel, das die meisten Aspekte von libmunin abdeckt, findet sich im Anhang, unter Ausführliches Beispiel.
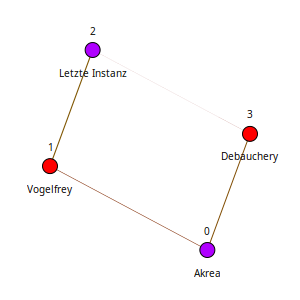
Figure 5.1: Minimaler Beispielgraph der hinter dem obigen Beispiel steht. Die Dicke der Kanten indiziert die Distanz. Dünne Kanten implizieren eine kleine Distanz. Die Farbe der Knoten ist hier nicht relevant.
5.2 Kurze Implementierungshistorie¶
Am 11. Oktober 2013 wurde mit der Implementierung begonnen. Anfangs war, wie im Exposé vorgesehen, noch eine Distanzmatrix zur Speicherung der Distanzen und das Berechnen jeder einzelnen Song–Kombination vorgesehen — aus den bereits erwähnten Gründen hat sich das zu einer Approximation geändert. Hierbei eine vernünftige Herangehensweise zu finden, hat letztlich ca. 1 \(^1/_2\) Monate beansprucht.
Die zwischenzeitlich aufgekommene Idee, Audiodaten mittels Audiofingerprints wie Chromaprint [Link–25] zu vergleichen wurde wieder aufgegeben. Damit ließen sich wirklich nur fast gleiche Stücke ermitteln. Selbst Live- und Studio–Versionen der Lieder ließen sich manchmal nicht differenzieren.
Parallel zur Implementierung wurde ein ,,Tagebuch" [Link–26] verfasst, das dazu dienen sollte Ideen und Geschehnisse festzuhalten, allerdings weniger als Information für Dritte, mehr als persönliches Notizheft.
Nach gut drei Monaten wurde am 15. Januar 2014 der erste Prototyp fertiggestellt. Die letzten 3 \(^1/_2\) Wochen dieser Zeit wurden für die Implementierung einer Demo–Anwendung aufgewendet.
5.3 Liste verfügbarer Empfehlungs–Strategien¶
Basierend auf einem Seedsong: Basierend auf einem vom Endnutzer ausgewählten Song wird ein Iterator zurückgegeben, der gemäß Kapitel 4.1.3 eine Breitensuche von diesem Seedsong aus ausführt. Optional wird der Iterator gemäß Kapitel 4.1.4 gefiltert.
Basierend auf einer Heuristik: libmunin kann auch automatisch einen oder mehrere geeignete Seedsongs auswählen. Dabei wird der Reihe nach das Folgende probiert:
- Wähle die Regel mit der besten Bewertung aus und nehme alle darin erwähnten Songs als Seedsongs an.
- Wähle den Song mit der höchsten Abspielanzahl als Seedsong.
- Schlägt beides schief weil keine Regeln vorhanden sind oder noch nichts abgespielt wurde, so wird ein zufälliger Seedsong gezogen.
Optional wird der entstehende Iterator gemäß Kapitel 4.1.4 gefiltert.
Basierend auf einer Attributsuche: Es kann nach einen oder mehreren Songs gesucht werden die gewisse Attribut–Werte–Paare aufweisen. Als Beispiel kann ein Song gesucht werden der die Merkmale ,,Genre: Rock" und ,,Date: 2012" aufweist.
Alle passenden Songs, aber maximal 20, werden dann als Seedsongs angenommen. Optional wird der entstehende Iterator gemäß Kapitel 4.1.4 gefiltert.
5.4 Liste der Provider¶
Insgesamt wurden 13 unterschiedliche Provider und 9 Distanzfunktionen implementiert. Davon variieren einige allerdings nur in Details.
Die genaue Funktionsweise der Provider wird in der Bachelorarbeit betrachtet. Im Folgenden wird nur eine Auflistung verfügbarer Provider gegeben und welche Eingabe sie erwarten, sowie welche Ausgabe sie produzieren.
Date: Wandelt und normalisiert ein Datum, das als String übergeben wird zu einer Jahreszahl (1975 beispielsweise). Dabei werden die häufigsten Datumformatierungen automatisch erkannt. Dies ist nötig, da je nach Region ganz unterschiedliche Datumsangaben in den Audiofiles getaggt sind.
Moodbar: Berechnet mit dem moodbar (vgl. [10]) Programm aus einem beliebigen Audio File einen Vektor mit 1000 RGB–Farbwerten (siehe Abb. 5.2). Jeder dieser Farbwerte repräsentiert den Anteil niedriger (rot), mittlerer (grün) und hoher Frequenzen (blau) in einem Tausendstel der Audiodaten.
Obwohl man aus dem Namen dieses Verfahrens schließen könnte, dass hier die Stimmung im Lied angedeutet wird, kann man aus diesen Informationen lediglich herauslesen, wie ,,energiegeladen" die Stimmung in einem Lied zu einem bestimmten Zeitpunkt ist, mit etwas Glück kann man auch Instrumente erkennen, so ist die Kombination von E–Gitarre und Drums oft ein helles Türkis. Akustikgitarren hingegen erscheinen meist in einem dunklem Orange.
Aus diesem RGB–Vektoren werden die prägnantesten Merkmale abgeleitet: die dominanten Farben, der Stilleanteil (schwarz) und einige weitere Merkmale.
Dieser Provider kommt in drei verschiedenen Ausführungen daher, die sich in dem Typ ihrer Eingabe unterscheiden:
- Moodbar: Nimmt eine Liste von 1000 RGB–Werten.
- MoodbarFile: Nimmt einen Dateipfad zu einer von der moodbar erstellten Datei entgegen die einen Vektor aus 1000 RGB–Werten binär beinhaltet.
- MoodbarAudioFile: Nimmt einen Dateipfad zu einer beliebigen Audiodatei entgegen und führt das moodbar-Utility darauf aus, falls noch keine weitere Datei mit demselben Dateipfad plus der zusätzlichen Endung .mood vorhanden ist.

Figure 5.2: Anzeige des RGB-Vektors samt Histogramm und Verlauf für das Lied ,,Over Nine Waves" der Band ,,Suidakra". Der grüne Teil am Anfang ist ein Dudelsack–Intro. Bei 30% setzen relativ plötzlich harte E–Gitarren und Drums ein, die in verschiedenen Variationen durch das ganze Lied gehen. Musik–Link auf YouTube: [Link–27].
Wordlist: Bricht einen String in eine Liste von Wörtern auf.
BPM: Berechnet die ,,Beats–Per–Minute" eines Lieds, also einem Maß für die Schnelligkeit. Dies funktioniert nicht nur für stark beatlastige Musikrichtungen wie Techno, sondern auch für normale Musik mit herkömmlichen Instrumenten.
Die Funktionalität wird momentan, eher primitiv, durch den Aufruf eines externen Tools, namens bpm-tools realisiert [Link–28].
Normalize, ArtistNormalize, AlbumNormalize, TitleNormalize: Diese Provider normalisieren die häufig unsauberen Tags einer Musiksammlung auf verschiedene Art und Weise:
- Normalize: Normalisiert einen String mittels NKFC Unicode Normalization. Bei Unicode gibt es oft mehrere Arten einen Glyph zu schreiben. So kann ein ä als einzelner Glyph (Codepoint U+e4) oder als Composite Glyph geschrieben werden: "+a (U+30B + U+61). Dieser Provider macht daraus stets den ersten Fall.
- ArtistNormalize: Entfernt zusätzlich Unrat (welcher beim Vergleichen stört) der oft bei Artist–Tags vorhanden ist. Beispielsweise wird aus ,,The Beatles" der String ,,beatles"
- AlbumNormalize: Entfernt analog zu ArtistNormalize Unrat aus Album–Namen wie ,,(live 2012)" .
- TitleNormalize: Momentan ein Synonym für AlbumNormalize.
Composite: Erlaubt das Verketten von Providern. Der erste Eingabewert wird dem ersten Provider in der Kette gegeben und die Ausgabe, ähnlich wie bei einer Unix–Pipe, wird an den nächsten Provider in der Kette als Eingabe weitergegeben.
Ein Anwendungsbeispiel wäre das Zusammenschalten mehrerer Provider nach Baukastenprinzip:
![digraph foo {
size=5;
node [shape=record];
subgraph {
rank = same; PlyrLyrics; Keywords; Stem
}
"Eingabe: Artist, Album" -> PlyrLyrics [label=" Sucht im Web "]
PlyrLyrics -> Keywords [label="liefert Songtext"]
Keywords -> Stem [label="extrahiert Keywords"]
Stem -> "Ausgabe: Stemmed Keywords" [label=" Wortstamm--Keywords "]
}](../../_images/graphviz-930912a032f10249dcffed35664779fd4ae53789.png)
Stem: Bringt mithilfe des Porter–Stemmer–Algorithmus ([Link–29]) einzelne Wörter oder eine Liste von Wörtern auf ihren Wortstamm zurück. Aus den Wörtern Fisher, Fish, fishing wird beispielsweise stets fish. Dies ist natürlich abhängig von der Eingabesprache. Momentan wird aber stets Englisch angenommen.
GenreTree: Der wohl komplizierteste Provider. Ein beliebiges Eingabegenre wird in einzelne Untergenres aufgeteilt und normalisiert. Beispielsweise wird die Genrebeschreibung Rock, Reggae / Alternative Rock mittels eines regulären Ausdrucks in die Unterbestandteile aufgebrochen: Rock, Reggae und Alternative Rock.
Danach wird jedes so entstandene Untergenre in einzelne Wörter aufgebrochen und in einem Baum bekannter Genres (momentan 1876 einzelne Genres) eingepasst:
![digraph foo {
size=3;
node [shape=record];
"music (#0)" -> "rock (#771)"
"music (#0)" -> "alternative (#14)"
"music (#0)" -> "reggae (#753)"
"rock (#771)" -> "alternative (#3)"
}](../../_images/graphviz-c65f905c3bb28504a5ae66c84178cf750ae33936.png)
Hier werden aus Platzgründen nur die Untergenres im obigen Beispiel gezeigt. Jeder Knoten hat zudem einen Indexwert der in Klammern angegeben ist. Das finale Resultat dieses Providers mit der obigen Eingabe, ist dann in Python–Listen Notation:
[[14], [771, 3], [753], [771]]
Das Resultat ist also eine Liste mit einzelnen Pfaden durch den Genrebaum. Jeder Pfad ist dabei eine Liste von mindestens einem Indexwert. Da der Wurzelknoten (music) immer den Index 0 hat, wird dieser weggelassen. Löst man diese wieder auf, so erhält man die ursprünglichen Genres:
[['alternative'], ['alternative', 'rock'], ['reggae'], ['rock']]
Da die einzelnen Pfade allerdings weniger Speicher verbrauchen und sich bei weitem leichter auflösen und vergleichen lassen, werden diese vom Provider zurückgegeben.
Keywords: Extrahiert aus einem Text als Eingabe alle relevanten Stichwörter. Ein Beispiel dieser Keywords wird in Tabelle 5.3 gezeigt. Zudem wird die Sprache des Eingabetextes erkannt und mit abgespeichert.
Rating Keywords 22.558 yellow, submarin 20.835 full, speed, ahead, mr 8.343 live, beneath 5.247 band, begin 3.297 sea 3.227 green 2.797 captain ... ... Figure 5.3: Die extrahierten Keywords aus ,,Yellow Submarine”, samt deren Rating. Das Rating soll hier nicht weiter erklärt werden.
PlyrLyrics: Beschafft mittels libglyr Liedtexte aus dem Internet. Bereits gesuchte Liedtexte werden dabei zwischengespeichert. Dieser Provider eignet sich besonders im Zusammenhang mit dem Keywords–Provider zusammen als Composite–Provider.
DiscogsGenre: Beschafft von dem Online–Musikmarktplatz Discogs Genre Informationen. Dies ist nötig, da Musiksammlungen für gewöhnlich mittels einer Online–Musikdatenbank getaggt werden — die meisten bieten aber leider keine Genreinformationen.
5.5 Liste der Distanzfunktionen¶
Die genaue Funktionsweise der einzelnen Distanzfunktionen wird in der Bachelorarbeit genauer betrachtet. Im Folgenden wird aber eine kurze Auflistung jeder vorhandenen Distanzfunktion und der Annahme auf der sie basiert gegeben.
Date: Vergleicht zwei Jahreszahlen. Eine hohe Differenz führt dabei zu einer hohen Distanz. Also ,,erstes" Jahr wird das Jahr 1950 angenommen.
Annahme: Lieder mit einer großen zeitlichen Differenz zueinander werden selten zusammen gehört.
Moodbar Vergleicht die moodbar zweier unterschiedlicher Lieder.
Annahme: Ähnliche Moodbars implizieren auch ähnliche Lieder. Da man oft gewisse Instrumente anhand deren Farbe erkennen kann werden unter anderen die dominanten Farben und der Stilleanteil verglichen.
Rating: Vergleicht ein vom Benutzer vergebenes Rating. Dabei wird zwischen nicht gesetzten (z.B. 0) und gesetzten Rating unterschieden (z.B. 1-5) die sich unterschiedlich auf die finale Distanz auswirken. Die Werte für das Minima, Maxima und den Nullwert können beim Erstellen der Session konfiguriert werden.
Annahme: Zeichnet der Benutzer ein Lied mit einem hohen Rating aus, so möchte er vermutlich Empfehlungen zu ebenfalls hoch ausgezeichneten Liedern haben. Dies bietet dem Nutzer eine Möglichkeit direkte Hinweise an libmunin zu geben (Stichwort explizites Lernen).
BPM: Vergleicht den ,,Beats-per–Minute`` Wert zweier Lieder. Als Minimalwert wird 50 und als Maximalwert 250 angenommen.
Annahme: Ähnlich schnelle Lieder werden oft zusammen gespielt.
Wordlist: Vergleicht eine Menge von Wörtern auf Identität. Sind die Mengen identisch, so kommt eine Distanz von \(0\) dabei heraus.
Annahme: Diese Distanzfunktion ist beispielsweise beim Vergleich von Titeln nützlich. Ähnliche Wörter in Titeln deuten oft auf ähnliche Themen hin. Als Beispiel kann man die Titel ,,Hey Staat" (Hans Söllner) und ,,Lieber Staat" (Farin Urlaub) nennen.
Levenshtein: Wie Wordlist, die einzelnen Wörter werden aber mittels der Levenshtein–Distanzfunktion [1] verglichen. So spielen kleine Abweichungen, wie der Vergleich von color und colour, keine große Rolle mehr. Der große Nachteil ist der erhöhte Rechenaufwand.
Annahme: Ähnlich wie bei Wordlist, aber eben auch für Daten bei denen man kleine Unterschiede in der Schreibweise erwartet. Beispielsweise bei Künstlern ZZ-Top und zz Top.
Keywords: Nimmt die Ergebnisse des Keyword–Providers entgegen und bezieht die Sprache beider Keywordmengen sowie die Länge der einzelnen Keywords in die Distanz mit ein.
Annahme: Der Nutzer möchte Lieder mit ähnlichen Themen zu einem Lied vorgeschlagen bekommen, oder wenigstens in derselben Sprache.
GenreTree, GenreTreeAvg: Vergleicht die vom GenreTree–Provider erzeugten Genrepfade.
GenreTree: Vergleicht alle Pfade in beiden Eingabemengen miteinander und nimmt die geringste Distanz von allen.
Diese Distanzfunktion sollte gewählt werden, wenn die Genre–Tags eher kurz gefasst sind. Beispielsweise wenn nur Rock darin steht.
GenreTreeAvg: Vergleicht alle Pfade in beiden Eingabemengen miteinander und nimmt die durchschnittliche Distanz von allen.
Diese Distanzfunktion sollte gewählt werden, wenn ausführliche Genre–Tags vorhanden sind — wie sie beispielsweise vom DiscogsGenre–Provider geliefert werden.
Annahme: Viele Hörer bleiben oft innerhalb eines Genres.
5.6 Modul– und Paketübersicht¶
| Verzeichnisse | (gekürzt) | Beschreibung | ||
|---|---|---|---|---|
| munin/ | Quelltextverzeichnis | |||
| __init__.py | Versionierungs Info | |||
| __main__.py | Beispielprogramm | |||
| database.py | Implementierung von Database | |||
| dbus_service.py | Unfertiger DBus Service. | |||
| dbus_client | Unfertiger DBus Beispielclient. | |||
| distance/ | Unterverzeichnis für Distanzfunktionen | |||
| __init__.py | Implementierung von DistanceFunction | |||
| bpm.py | Implementierung von BPMDistance | |||
| date.py | Implementierung von DateDistance | |||
| ... | Weitere Subklassen von DistanceFunction | |||
| session.py | Implementierung der Session (API) | |||
| easy.py | Implementierung der EasySession | |||
| graph.py | Implementierung der Graphenoperationen | |||
| helper.py | Gesammelte, oftgenutzte Funktionen | |||
| history.py | Implementierung der History u. Regeln | |||
| plot.py | Visualisierungsfunktionen für Graphen | |||
| provider/ | Unterverzeichnis für Provider | |||
| __init__.py | Implementierung von Provider | |||
| bpm.py | Implementierung von BPMProvider | |||
| composite.py | Implementierung des CompositeProvider | |||
| ... | Weitere Subklassen von Provider | |||
| rake.py | Implementierung des RAKE-Algorightmus | |||
| scripts/ | Unterverzeichnis für ,,Test Scripts" | |||
| visualizer.py | Zeichnet ein mood-file mittels cairo | |||
| walk.py | Berechnet vieles mood-files parallel | |||
| song.py | Implementierung von Song | |||
| stopwords/ | Stoppwortimplementierung: | |||
| __init__.py | Implementierung des StopwordsLoader | |||
| data/ | Unterverzeichnis für die Stoppwortlisten | |||
| de | Gemäß ISO 638-1 benannte Dateien; | |||
| en | Pro Zeile ist ein Stoppwort gelistet; | |||
| es | Insgesamt 17 verschiedene Listen. | |||
| ... | ||||
| testing.py | Fixtures und Helper für Unit–Tests |
Figure 5.4: Verzeichnisbaum mit den einzelnen Modulen von libmunin's Implementierung
In der Programmiersprache Python entspricht jede einzelne .py Datei einem Modul. Die Auflistung unter Tabelle 5.4 soll eine Übersicht darüber geben, welche Funktionen in welchem Modul implementiert worden.
Anmerkung: __init__.py ist eine spezielle Datei, die beim Laden eines Verzeichnisses durch Python ausgeführt wird.
5.7 Trivia¶
5.7.1 Entwicklungsumgebung¶
Als Programmiersprache wurde Python, in Version \(3.2\), aus folgenden Gründen ausgewählt:
- Exzellenter Support für Rapid Prototyping — eine wichtige Eigenschaft bei nur knapp drei Monaten Implementierungszeit.
- Große Zahl an nützlichen Bibliotheken, besonders für den wissenschaftlichen Einsatz.
- Bei Performanceproblemen ist eine Auslagerung von Code nach \(\mathrm{C/C{\scriptstyle\overset{\!++}{\vphantom{\_}}}}\) mittels Cython sehr einfach möglich.
- Der Autor hat gute Erfahrungen mit Python in mehreren Projekten gesammelt.
Alle Quellen die während dieses Projektes entstanden sind, finden sich auf der sozialen Code–Hosting Plattform GitHub [Link–30]. Zur Versionierung der Quelltexte wird entsprechend das Distributed Version Control System git genutzt.
Der Vorteil dieser Plattform besteht darin, dass sie von sehr vielen Entwicklern besucht wird, die die Software ausprobieren und möglicherweise verbessern (durch sogenannte Forks und Pull Requests) oder sich zumindest die Seite für spätere Projekte merken.
Die dazugehörige Dokumentation wird bei jedem Commit 2 automatisch aus den Quellen, mittels des freien Dokumentations–Generators Sphinx, auf der für Python–Projekte populären, Dokumentations–Hosting–Plattform ReadTheDocs gebaut und dort verfügbar gemacht. [Link–24]
Zudem werden pro Commit Unit–Tests auf der Continious–Integration Plattform TravisCI [Link–31] für verschiedene Python–Versionen durchgeführt. Dies hat den Vorteil, dass fehlerhafte Versionen aufgedeckt werden, selbst wenn man vergessen hat, die Unit-Tests lokal durchzuführen.
Figure 5.5: Screenshot der Statusbuttons auf der Github–Seite.
Schlägt der Build fehl, so färben sich kleine Buttons in den oben genannten Diensten rot und man wird per Mail benachrichtigt (Siehe Abb. 5.5). Versionen die als stabil eingestuft werden, werden auf PyPi (Python Package Index) veröffentlicht [Link–32], wo sie mithilfe des folgenden Befehles samt Python–Abhängigkeiten installiert werden können (Setzt Python \(\ge 3.2\) vorraus):
$ sudo pip install libmunin
Auf lokaler Seite wird jede Änderungen versioniert, um die Fehlersuche zu vereinfachen. Im Notfall kann man stets auf funktionierende Versionen zurückgehen.
Der Quelltext selber wird in gVim geschrieben. Um sich an die gängigen Python–Konventionen zu halten, wird bei jedem Speichern der Quelltext mit den Zusatzprogrammen PEP8 und flake8 statisch überprüft.
Auch dieses Dokument wurde mit dem LaTeX -Backend einer modifizierten Sphinxversion erstellt. Der Vorteil ist dabei, dass die Arbeit in reStructuredText geschrieben werden kann und einerseits als PDF- und als HTML–Variante [Link–33] erstellt wird — letztere- ist sogar für mobile Endgeräte ausgelegt.
5.7.2 Abhängigkeiten von libmunin¶
| Abhängigkeit | PyPI? | Optional? | Referenz | Aufgabe |
|---|---|---|---|---|
| moodbar | \(\checkmark\) | [10] | Moodbar–Berechnung. | |
| bpm-utils | \(\checkmark\) | [Link–28] | BPM–Berechnung. | |
| plyr | \(\checkmark\) | \(\checkmark\) | [Link–17] | Liedtextbeschaffung. |
| python-igraph | \(\checkmark\) | \(\checkmark\) | [Link–22] | Graphenplotting. |
| pymining | \(\checkmark\) | Datamining–Hilfsfunktionen. | ||
| bidict | \(\checkmark\) | Bidirektionale Hashtabelle. | ||
| guess_language | \(\checkmark\) | Spracherkennung. | ||
| pyenchant | \(\checkmark\) | \(\checkmark\) | Verbesserte Spracherkennung. | |
| magicdate | \(\checkmark\) | Datumsformaterkennung. | ||
| pyxDamerauLevenshtein | \(\checkmark\) | Levenshtein–Distanzfunktion. |
Figure 5.6: Übersicht über die Abhängigkeiten von libmunin. Es wird angezeigt ob das Paket auf PyPI vorhanden ist und ob es rein optionale Funktionalität bereitstellt.
In Tabelle 5.6 wird eine Übersicht über die direkten Abhängigkeiten von libmunin gegeben. Abhängigkeiten von Drittanbietern sind nicht aufgelistet. Auf die Abhängigkeiten ohne Referenz wird noch in der Bachelorarbeit genauer eingegangen. Die auf PyPI gelisteten Pakete werden automatisch mit dem libmunin–Paket installiert. Die anderen Pakete müssen über das Paketsystem der verwendeten Distribution, oder aus den Quellen installiert werden.
5.7.3 Unit–Tests¶
Die meisten Module sind mit unittests ausgestattet, die sich, für Python typisch, am Ende von jeder .py–Datei befinden:
def func(): return 42
# Tests werden nur ausgeführt wenn das Skript direkt ausgeführt wird.
if __name__ == '__main__':
import unittest
class TestFunc(unittest.TestCase): # Ein einzelner Unittest:
def test_func(self): self.assertEqual(func(), 42)
unittest.main() # Führe tests aus.
Auf einer detaillierten Erklärung der im einzelnen getesteten Funktionalitäten wird verzichtet. Diese würden den Rahmen der Projektarbeit ohne erkenntlichen Mehrwert sprengen.
5.7.4 Lines of Code (LoC)¶
Was die Lines of Code betrifft so verteilen sich insgesamt 4867 Zeilen Quelltext auf 46 einzelne Dateien. Die im nächsten Kapitel vorgestellte Demo–Anwendung ist dabei mit eingerechnet. Dazu gesellen sich 2169 Zeilen Kommentare, die zum größten Teil zur Generation der Online–Dokumentation genutzt werden.
Dazu kommen einige weitere Zeilen von reStructuredText (einer einfachen, aber mächtigen Markup–Sprache) die das Gerüst der Online–Dokumentation bilden:
$ wc -l $(find . -iname '*.rst')
2231 insgesamt
Die Online–Dokumentation wird aus den Kommentaren im Quelltext extrahiert. Das entspricht dem vom Donald Knuth vorgeschlagenem Ansatz des Literate Programming.
5.7.5 Sonstige Statistiken¶
Zudem lassen sich einige Statistiken präsentieren, die aus dem git log generiert wurden:
GitHub Visualisierungen: GitHub stellt einige optisch ansprechende und interaktive Statistiken bereit die beispielsweise viel über den eigenen Arbeitszyklus verraten: [Link–34].
gitstats Visualisierungen: Das kleine Programm gitstats baut aus dem git log eine HTML-Seite mit einigen interessanten Statistiken, wie beispielsweise der absoluten Anzahl von geschriebenen (und wieder gelöschten) Zeilen: [Link–33].
Commit–Graph Visualisierungsvideo: gource ist ein Programm, das in einem optisch ansprechenden Video zeigt wie sich das git-Repository mit der Zeit aufbaut. Unter [Link–35] findet sich ein ein–minütiges Video dass entsprechend die Entwicklung von libmunin zeigt.
Footnotes
| [1] | sudo pip install libmunin – bisher nur auf Entwicklersystem getestet! |
| [2] | In einem Commit werden eine Reihe zusammengehöriger Änderungen verpackt. Später kann man einen Commit immer wieder zurückspulen. |