5 Implizites Lernen vom Nutzer¶
5.1 Generierung von Regeln¶
In vorangegangenen Kapiteln wurde schon oft davon gesprochen, dass libmunin den Nutzer beobachtet. Dies geschieht, indem der Anwendungsentwickler, die vom Nutzer gehörten Titel, an libmunin zurückmeldet.
5.1.1 Finden von wiederkehrenden Mustern¶
Um eine ,,Warenkorbanalyse" durchzuführen, braucht man erstmal Warenkörbe. Diese entstehen, indem man die einzelnen Songs in der Historie zeitlich gruppiert. Wächst eine Gruppe über eine Grenze (momentan \(5\)), so wird eine neue Gruppe begonnen.
Diese einzelnen Gruppen von Songs fungieren dann als Warenkörbe. Aus diesen gilt es zuerst eine Menge an Songs (im Folgenden Muster 1 genannt) zu finden, die jeweils oft zusammen in den einzelnen Warenkörben vorkommen. Der naive Ansatz wäre, für jede Kombination der Eingabesongs, das Vorkommen derselben, im Warenkorb zu zählen. Wie man sich bereits denken kann, ist hierfür der algorithmische Aufwand enorm, denn bereits bei einer Menge von \(1000\) unterschiedlichen Songs in der Historie, müssten bereits \(2^{n}-1\) Kombinationen gebildet werden. Denn ein Warenkorb kann man als einer Menge von sich nicht wiederholender Songs sehen, bei der auch die Reihenfolge keine Rolle spielt.
Für die Lösung dieses Problems, gibt es einige etablierte Algorithmen. Der bekannteste ist vermutlich der Apriori–Algorithmus (vergleiche [9], S. 248–253). Statt alle Kombinationen zu betrachten, werden erst alle ,,Einer–Kombinationen" gebildet und die ausgefiltert, welche einen zu niedrigen Support–Count besitzen. Die Grenze legt man vorher fest. Der Support–Count \(support(A)\) ist die Anzahl der Warenkörbe, in denen die Menge von Songs \(A\) vorkommt, geteilt durch die absolute Anzahl der Warenkörbe. Danach werden mit den verbliebenen Zweier–Kombination gebildet, wieder gefiltert, dann die noch relevanten Dreier–Kombinationen und so weiter. Dadurch wird eine große Menge von Kombinationen vermieden.
Seit einiger Zeit haben sich jedoch eine Gruppe effizienterer Algorithmen etabliert. Dazu gehören der FP–Growth (siehe [9] S. 257–259, 272), Eclat (siehe [10]), sowie der hier verwendete RELIM–Algorithmus, der in [11] vorgestellt wurde.
| Kombination (1er) | Kombination (2er) | Kombination (3er) | |||
|---|---|---|---|---|---|
| A | 1 \(\times\) | A, B | 1 \(\times\) | A, B, C | 1 \(\times\) |
| B | 3 \(\times\) | B, C | 3 \(\times\) | ||
| C | 3 \(\times\) | C, A | 1 \(\times\) |
Figure 5.1: Die Muster, welche aus den drei Warenkörben {{A, B, C} {B, B, C}, {C, C, B}} generiert worden sind, mit der jeweiligen Anzahl von Vorkommnissen in den Warenkörben.
In Tabelle 5.1 sieht man ein Beispiel aus drei Warenkörben, aus denen per Hand mit der naiven Herangehensweise alle möglichen Kombinationen samt deren Support–Count, aufgelistet worden sind.
5.1.2 Der RELIM–Algorithmus¶
Generell gilt FP–Growth als der neue Standard–Algorithmus, der laut mehrerer Quellen andere Algorithmen wie Eclat und RELIM (RE–cursive ELIM–ination) aussticht [12] [13]. In diesem Fall wird trotzdem auf RELIM zurückgegriffen, da dieser für die Zwecke des Autors ausreichend schnell ist und die Datenmenge nie mehr als wenige tausend Songs übersteigen wird. Zudem gibt es mit dem Python–Paket pymining (siehe [Link–19]) bereits eine freie, qualitativ hochwertige Implementierung, während es für FP–Growth nur qualitativ schlechte Implementierungen zu geben scheint, oder welche, die nur für Python–Versionen \(\leq 2,7\) funktionieren.
5.1.3 Ableitung von Regeln aus Mustern¶
Hat man eine Gruppe von häufig zusammen auftretenden Song–Kombinationen gefunden, so können daraus Assoziationsregeln abgeleitet werden. Eine Assoziationsregel verbindet zwei Mengen A und B von Songs mit einer gewissen Wahrscheinlichkeit miteinander. Sie besagen, dass wenn eine der beiden Mengen miteinander gehört wird, dann ist es wahrscheinlich, dass auch die andere Menge daraufhin angehört wird. Regeln werden aus dem Verhalten des Nutzers abgeleitet. Dazu wird jedes Lied, das der Nutzer anhört, in einer Historie zwischengespeichert. Um die generelle Anwendbarkeit der Regel zu beschreiben, wird für jede Regel ein Rating berechnet.
Anmerkung: Im allgemeinen Gebrauch sind Assoziationsregeln nur in eine Richtung definiert. In libmunin sind die Regeln aus Gründen der Einfacheit allerdings bidirektional. So gilt nicht nur, dass man wahrscheinlich die Menge B hört, wenn man A gehört hat (\(A \rightarrow B\)), sondern auch umgekehrt (\(A \leftrightarrow B\)). Ein natürlichsprachliches Beispiel hierfür: \(\frac{2}{3}\) der Basketballspieler essen Cornflakes (\(Basketball \Rightarrow Cornflakes\)). Diese Regel besagt, dass der größere Teil der Basketballspieler Cornflakes isst, aber nicht, dass die meisten Cornflakes–Esser Basketballspieler sind. Da bei libmunin auf beiden Seiten der Regel immer der gleiche Typ (ein oder mehrere Songs) steht und die Beziehung immer ,,werden miteinander gehört" ist, wird hier vereinfachend eine bidirektionale Assoziation angenommen. Dies erlaubt ein Anwenden der Regeln in beide Richtungen.
Um nun aus einem Muster Regeln abzuleiten, teilt man es in alle möglichen verschiedenen, disjunkten Teilmengen auf — allerdings in maximal zwei Teilmengen. Diese beiden Teilmengen nimmt man als die beiden Mengen einer Assoziationsregel an und testet, mittels verschiedener Metriken, wie zutreffend diese ist.
| Assoziationsregel | Support | Imbalance Ratio | Kulczynski | Lift |
|---|---|---|---|---|
| \(\left\{A\right\} \leftrightarrow \left\{B\right\}\) | \(0,\overline{3}\) | \(0,\overline{6}\) | \(0,\overline{6}\) | 0 |
| \(\left\{B\right\} \leftrightarrow \left\{C\right\}\) | \(1,0\) | \(0\) | \(1\) | 0 |
| \(\left\{C\right\} \leftrightarrow \left\{A\right\}\) | \(0,\overline{3}\) | \(0,\overline{6}\) | \(0,\overline{6}\) | 0 |
| \(\left\{A\right\} \leftrightarrow \left\{B, C\right\}\) | \(0,\overline{3}\) | \(0,\overline{6}\) | \(0,\overline{6}\) | 0 |
| \(\left\{B\right\} \leftrightarrow \left\{A, C\right\}\) | \(0,\overline{3}\) | \(0\) | \(0,\overline{3}\) | 0 |
| \(\left\{C\right\} \leftrightarrow \left\{A, B\right\}\) | \(0,\overline{3}\) | \(0,\overline{6}\) | \(0,\overline{6}\) | \(0,\overline{8}\) |
Figure 5.2: Mögliche Regeln, die aus den drei Warenkörben erstellt werden können. Zusätzlich wird der dazugehörige Gesamt–Support–Count, sowie der Metriken Imbalance–Ratio, Kulczynski und Lift abgebildet.
Als Beispiel kann man wieder die Warenkörbe aus Tabelle 5.1 nehmen. Muster mit nur einem Song können nicht weiter aufgeteilt werden, daher müssen diese nicht weiter betrachtet werden. Die Zweier–Kombination sind leicht in zwei disjunkte Teilmengen aufteilbar. Für die Dreier–Kombinationen können mehrere mögliche Teilmengen erstellt werden. Die einzelnen möglichen Regeln werden in Tabelle 5.2 aufgelistet.
| Eigenschaft | \(Basketball\) | \(\overline{Basketball}\) | \(\sum\) |
|---|---|---|---|
| \(Cornflakes\) | 400 | 350 | 750 |
| \(\overline{Cornflakes}\) | 200 | 50 | 250 |
| \(\sum\) | 600 | 400 | 1000 |
Figure 5.3: Vierfeldertafel mit erfundenen Beispieldaten. Es werden 1000 Studenten untersucht, bei denen die Eigenschaften ,,Spielt Basketball” und ,,Isst Cornflakes” festgestellt worden sind.
Nicht jede Regel ist automatisch eine gute Regel. Ein gängiges Lehrbeispiel wäre hier die Regel \(Basketball \Rightarrow Cornflakes\), also eine Regel, die laut Tabelle 5.3 besagt, dass \(\frac{2}{3}\) aller Basketballspieler zum Frühstück Cornflakes essen. Der Anteil der Menschen die aber insgesamt Cornflakes essen liegt aber bei \(75\%\) — daher ist die Eigenschaft ,,Basketballspieler" sogar im Vergleich, zum durchschnittlichen Anteil von Cornflake–Essern, ein Gegenindiz für diese Eigenschaft.
Um solche kontraproduktiven Assoziationsregeln zu vermeiden, werden für jede Regel zwei Metriken errechnet. Die von libmunin genutzten Metriken wurden dem Buch Datamining Concepts and Techniques ([9], S. 268–271) entnommen: Die Kulczynski–Metrik und der Imbalance–Ratio.
Die Kulczynski–Metrik drückt die Güte der Regel als eine reelle Zahl im Bereich \(\lbrack 0, 1\rbrack\) aus, wobei \(1\) die beste Wertung ist. Grob ausgedrückt besagt die Metrik, wie zutreffend die Regel im Durchschnitt ist. A und B sind im Folgenden die beiden nicht–leeren Teilmengen der Regel:
Diese Metrik ist der Durchschnitt aus zwei Variationen einer anderen Metrik: Dem confidence–Measure (vergleiche [9], S. 254f.):
Diese Metrik gibt an, zu welchem Prozentsatz die Regel zutrifft. Ist der Quotient \(1\), so trifft die Regel bei jedem bekannten Warenkorb zu. Der Zähler \(support(A\cap B)\) beschreibt hier, wie oft sowohl A und B gleichzeitig in einem Warenkorb vorkommen. Bereits allein ist diese Metrik ein gutes Indiz für die Korrektheit einer Regel, die Kulczynski–Metrik prüft zusätzlich beide Seiten der Regel. Um zu zeigen wie sich die Kulczynski–Metrik berechnen lässt, können wir die obige Definition umstellen:
Diese Metrik allein reicht allerdings nicht für eine qualitative Einschätzung einer Regel. Zwar kann die Regel oft zutreffen, doch kann sie, wie im obigen Beispiel mit den Cornflakes, trotzdem kontraproduktiv sein. Daher wird mit dem Imbalance Ratio eine weitere Metrik eingeführt. Der Imbalance Ratio gibt im Bereich \(\lbrack 0, 1\rbrack\) an, wie unterschiedlich beide Seiten der Regel sind. Treten die Muster unterschiedlich oft auf, so steigt diese Metrik. Hier ist der beste Wert die \(0\), der Schlechteste eine \(1\). Er ist gegeben durch:
Sollte die Kulczynski–Metrik kleiner als \(0,\overline{6}\) sein oder der Imbalance–Ratio größer als \(0,35\), so wird die Regel fallen gelassen. Diese Grenzwerte wurden, mehr oder minder willkürlich, nach einigen Tests festgelegt. Sollte die Regel akzeptabel sein, dann werden beide Metriken in eine einzelne, leichter zu handhabende Rating–Metrik verschmolzen:
Dieses Rating wird genutzt, um die einzelnen Assoziationsregeln zu sortieren. Das finale Rating bewegt sich im Bereich \(\lbrack 0, 1\rbrack\), wobei \(1\) das höchste vergebene Rating ist.
Nach einigen Tests erwiesen sich beide Metriken aber nicht als ausreichend um schwache Regeln zu filtern. Daher wurde noch zusätzlich die Lift–Metrik eingeführt (vergleiche [9], S.266). Diese ist definiert als:
Sie vergleicht das erwartete gemeinsame Auftreten der Mengen A und B mit dem tatsächlichen Auftreten in den Warenkörben. Ist der berechnete Wert \(< 0\), so korreliert das Auftreten von B negativ mit A. In diesem Fall wird die Regel ignoriert. Werte größer oder gleich \(0\) bedeuten eine positive/neutrale Korrelation. Das Auftreten von B impliziert das wahrscheinliche Auftreten von A. Für die unter Tabelle 5.3 gezeigten Werte können nun die einzelnen Metriken angewandt werden:
Dieses Ergebnis würde zum Ausschluss der Regel führen, da \(0,6 < 0.\overline{6}\) ist. Allerdings ist dies, für diese kontraproduktive Regel, ein knappes Ergebnis, da die Grenze von \(\overline{0,6}\) willkürlich gewählt wurde.
Beim ImbalanceRatio war \(0\) der beste anzunehmende Wert. Laut dem Ergebnis von \(0,16\) wäre diese Regel also sogar gut balanciert.
Der Lift führt mit einem Ergebnis \(< 0\) zu einer definitiven Filterung der Regel.
5.2 Anwendung von Regeln¶
Wie bereits unter Kapitel 3.2.2 erklärt, werden Assoziationsregel als Navigationshilfe beim Traversieren genutzt. Zu diesem Zwecke müssen die entstandenen Regeln irgendwo sortiert abgelegt werden. Diese Ablage ist der RuleIndex. Beim Einfügen wird jeweils überprüft, ob die Maximalanzahl an Regeln (momentan maximal \(1000\)) übertroffen wird. Sollte dem so sein, wird die älteste (ergo, zu erst eingefügte) Regel gelöscht, um Platz zu machen. Der Anwendungsentwickler kann mittels der lookup(song)–Methode eine Liste von Regeln abfragen, die diesen Song in irgendeiner Weise betreffen. Um diese Operation zu beschleunigen, wird intern eine Hashtabelle gehalten, mit dem Song als Schlüssel und der entsprechende Regel–Liste als zugehöriger Wert. Bei jeder Operation auf dem RuleIndex wird dieser automatisch bereinigt. Dabei werden Regeln entfernt, die Songs erwähnen, welche nicht mehr in der Historie vertreten sind.
5.3 Lernerfolg¶
Noch sind keine Aussagen darüber möglich, wie gut die momentane Lernstrategie funktioniert. Einerseits ist es schwer festzustellen was ,,gut" bedeutet, andererseits wurde eine libmunin–Session noch nie lange genug benutzt, um Aussagen über die Langzeitfunktionalität zu geben.
Daher ist die oben genannte Vorgehensweise als ,,Hypothese" zu sehen, die sich erst noch in der Praxis bewähren muss. Änderungen sind wahrscheinlich. Zudem muss auch auf Seite der Implementierung noch ein Detail verbessert werden: Momentan wird nur die Historie aufgezeichnet, wenn die Demonanwendung läuft. Da die Anwendung lediglich eine Fernbedienung für den MPD ist, läuft diese nicht die ganze Zeit über. Abhilfe würde ein separater MPD–Client, der nur dafür dient, im Hintergrund die Historie–Daten mitzuloggen.
5.4 Explizites Lernen¶
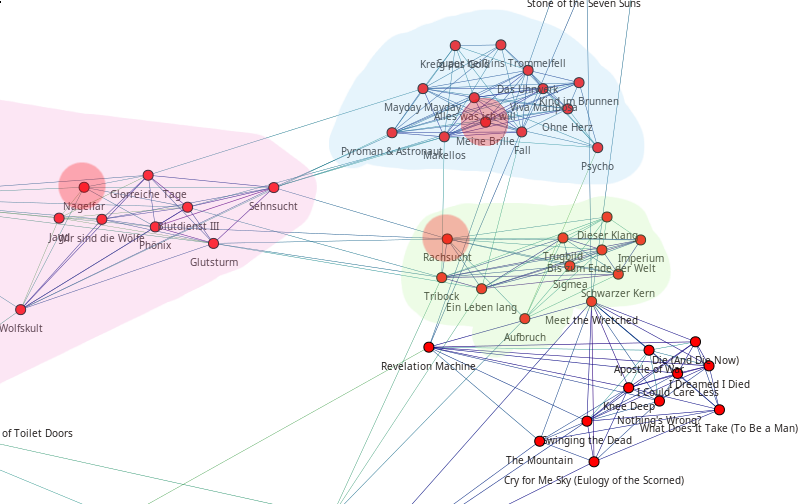
(a) Vor dem Vergeben der Ratings.
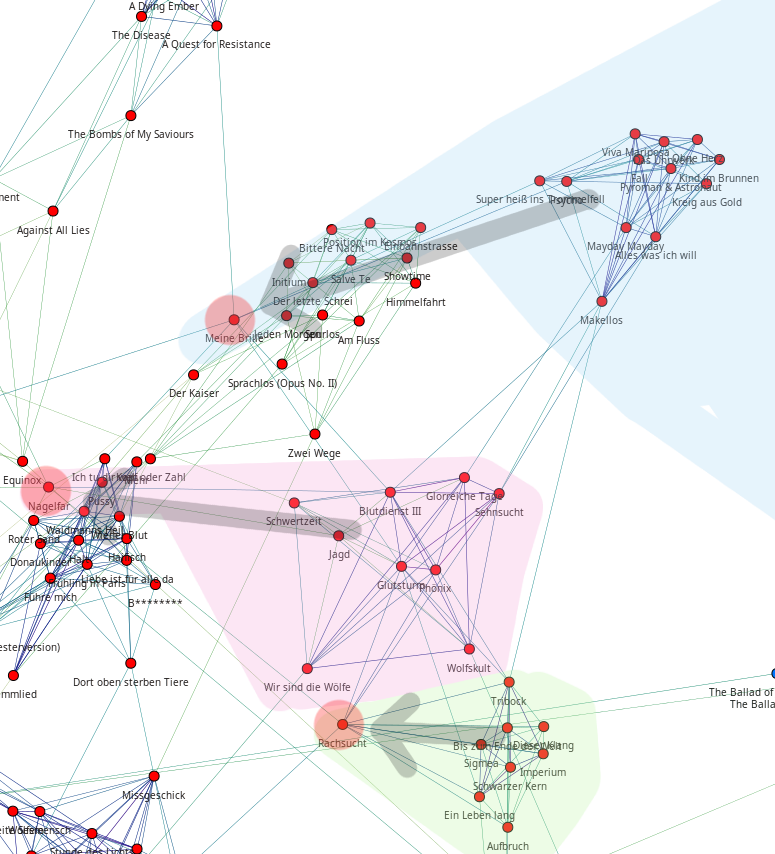
(b) Nach dem Vergeben der Ratings. Die Bewegung wird durch Pfeile angedeutet.
Figure 5.4: Vor und nach dem Vergeben von einem hohen Rating an drei Lieder (,,Rachsucht”, ,,Nagelfar”, ,,Meine Brille”, jeweils rot eingekreist). Die dazugehörigen Alben sind in rötlich, grünlich und bläulich hervorgehoben. Nach dem Vergeben sieht man, dass die entsprechenden Songs sich von den einzelnen Alben–Clustern räumlich entfernt haben und Verbindungen zu anderen Alben bekommen haben. Zudem haben sich die beiden erstgenannten Songs miteinander verbunden.
Bei einer insert–Operation lässt sich beobachten, dass die eingefügten Songs deutlich deutlich weitläufiger verbunden sind, als regulär per add hinzugefügte. Diese Eigenschaft macht sich die in der Projektarbeit ([1], S.37ff) gezeigte Demonanwendung zu Nutze: Ändert man das Rating eines Songs, so wird der Song mittels remove gelöscht und mittels insert an anderer Stelle wieder eingefügt. Meist verbindet sich dabei der Song, dann mit anderen ähnlich bewerteten Songs. Diese bilden ein zusätzliches Netz über dem Graphen, welches weitläufigere Sprünge ermöglicht. Dadurch hat der Nutzer eine Möglichkeit den Graphen seinen Vorstellungen nach umzubauen.
Unter Abbildung 5.4 soll dieses ,,explizite Lernen" nochmal visualisiert werden. Die dort abgebildete Verschiebung ist dadurch zu erklären, dass die insert–Operation meist einen anderen Punkt zum Wiedereinfügen findet. Durch Ändern des Ratings in der Demonanwendung, können daher einzelne Knoten gezielt im Graphen bewegt werden. Knoten mit ähnlichem Rating wandern näher zusammen und stellen ,,Brücken" zu anderen Alben–Clustern her. Man kann dieses Feature einerseits dazu nutzen, um seine Favoriten nahe im Graphen zusammenzupacken, andererseits, um unpassende Empfehlungen mit einem schlechten Rating abzustrafen. Letzeres hätteeine insert–Operation auf diesen Song zur Folge, wodurch er möglicherweise an anderer Stelle besser eingepasst wird.
Der ,,Mechanismus" des expliziten Lernens ist war mehr ein Nebeneffekt der Entwicklung. Zukünftige Versionen könnten leichter steuerbar und intuitiver verständliche Mechanismen anbieten. Ein Ansatz wäre der Weg, den Intelligente Playlisten bei vielen Music–Playern gehen: Der Nutzer stellt Beziehungen zwischen Attributen und Werten her. Ein Attribut wäre beispielsweise date, ein Wert 2010 und eine Beziehung \(\ge\). Weitere Beziehungen wären \(=\), \(\neq\), \(<\) oder \(\le\). Mit den unterschiedlichen Attributen, wären dann automatisch erstellte Playlisten wie ,,Favouriten" (\(rating > 3\)), ,,Ungehörte" (\(Playcount = 0\)) und ,,Neu Hinzugefügte" (\(date > (today - 7 \times days)\)) möglich. Für Letzere könnten hilfreiche Konstanten wie \(today\) eingeführt werden.
Footnotes
| [1] | In englischer Lektüre werden die Wiederkehrenden Muster als Frequent Itemsets bezeichnet. |