I/O & Syscalls
Speaking with the kernel 🐧
Agenda
- How to store bits?
- How does the kernel talk to the storage?
- How can we do I/O over syscalls?
- Profiling and benchmarking.
- Some performance tips.
Typical terms
- Latency: Time until the first drop of water arrives.
- Throughput: Current volume of water per time.
- Bandwidth: Maximum throughput. (liter/time)
Examples: | Low latency | High latency |
|---|---|---|
Low throughput | SDCards | SSHFS |
High throughput | SSD | HDD |
Fun fact: An extreme example of high latency with high throughput is IPoAC (IP over Avian Carrier), i.e. sticking an USB stick on a homing pidgeon. This was even standardized (jokingly): https://en.wikipedia.org/wiki/IP_over_Avian_Carriers
Hardware: HDDs

- Rotational, stacked disks with reading head.
- Reading head needs to seek to the right position.
- Elevator algorithm for ordering seeks.
- Performance loss at high or low temperature.
- Does not work if moved - bad for laptops.
- Dying, but battled tested & still widely used.
Big advantage: You could debug issues with too many seeks by audio!
Hardware: SSDs

- NAND Flash technology (like USB sticks)
- No expensive seek necessary.
- Limited number of write cycles.
- Becoming cheaper and better every year.
Write software for SSDs. There were some crazy tricks like FIEMAP to make applications re-order their reads in the order of how they are placed on disk. (Huge speedup on HDD, small speedup on SSD), but those will become pointless more and more.
SSD Write amplification
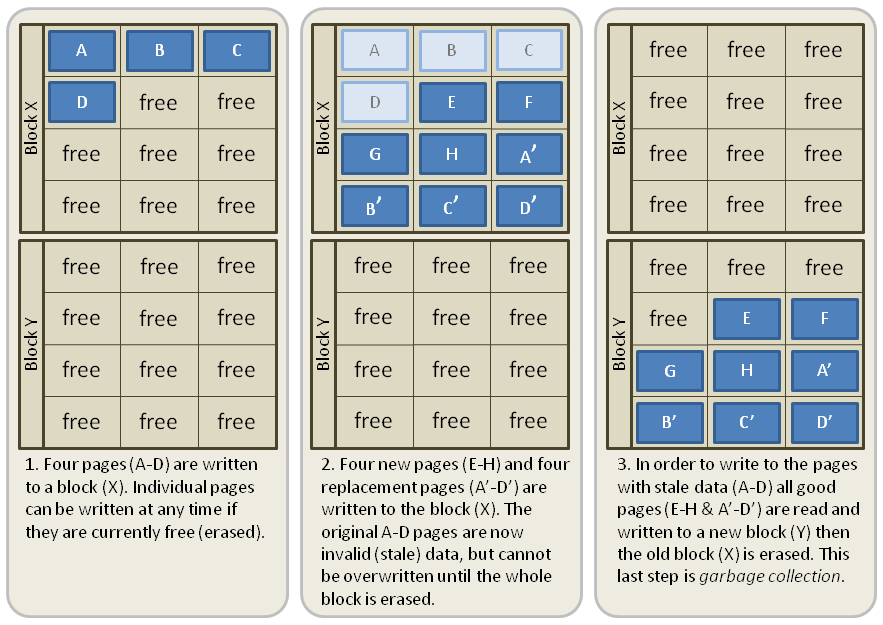
Source: http://databasearchitects.blogspot.com/2021/06/what-every-programmer-should-know-about.html?m=1
SSDs are divided into blocks (512kb), which are divided into pages (often 4K). Pages can be read or overwritten. Pages cannot be erased, only blocks can be. Updates of a pages are written to new blocks. If space runs out, old blocks with many stale pages are erased and can be re-used. The number of physical writes is therefore higher than the number of logical writes. The more space is used, the higher the write amplication factor though.
What we can do about it: Buy bigger SSDs than you need. Also avoid rewriting pages if possible. Secret: SSD have some spare space to keep working they don't tell you about.
Also enable TRIM support if your OS did not yet, but nowadways always enabled. This makes it possible for the OS to tell the SSD additional blocks that are not needed anymore.
Kill it with Hardware: RAID0
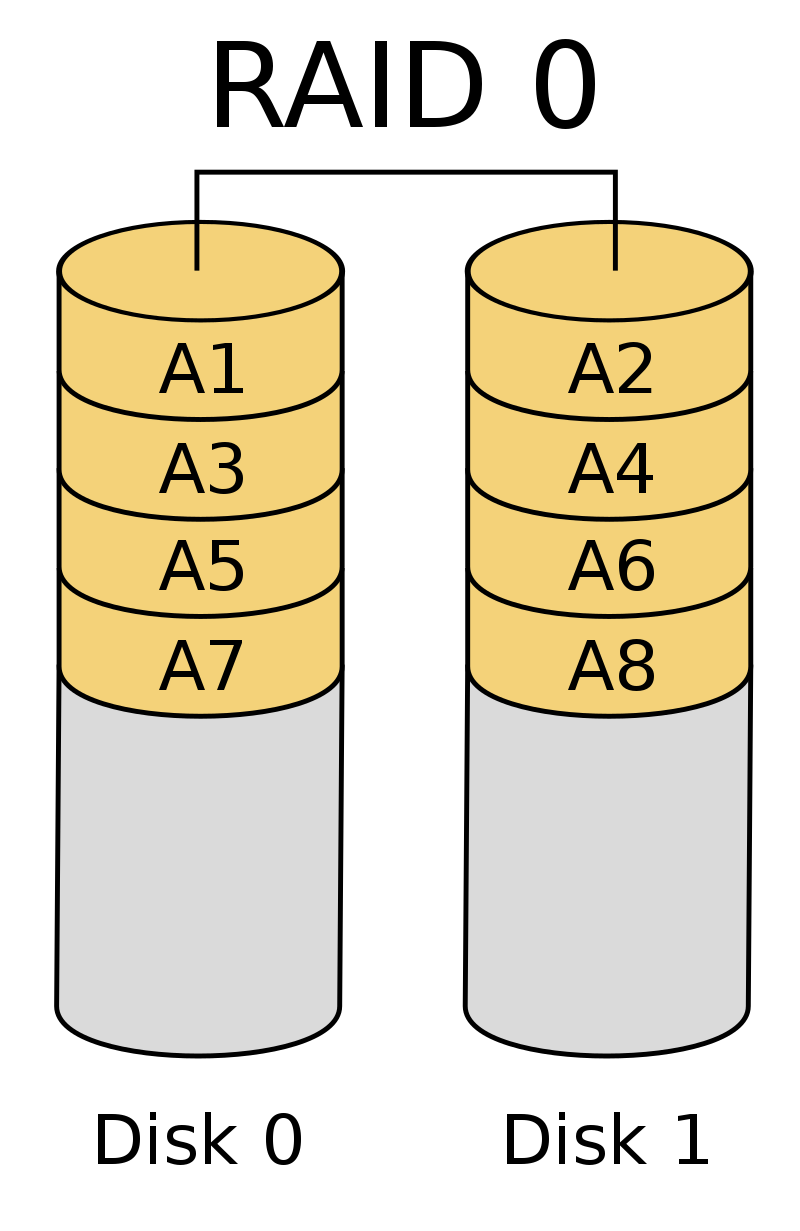
Let's be honest: I/O is one of the cases where it's the easiest to kill the problem by throwing a lot of hardware on it. The easiest way to increase the available bandwidth is using a RAID0, i.e. coupling several disk to build one logical unit out of them. Depending on your usecase you can of course use other raid levels:
https://en.wikipedia.org/wiki/Standard_RAID_levels
But that's not the point of this workshop. The point is how you can increase the throughput of your applications so you're able to reach this bandwidth (and maybe also on how you can defer having to buy more hard disks).
Everything is a file
Even memory is a file: /dev/mem Or a complete usb stick: /dev/sda Or randomnes: /dev/urandom
Virtual File System
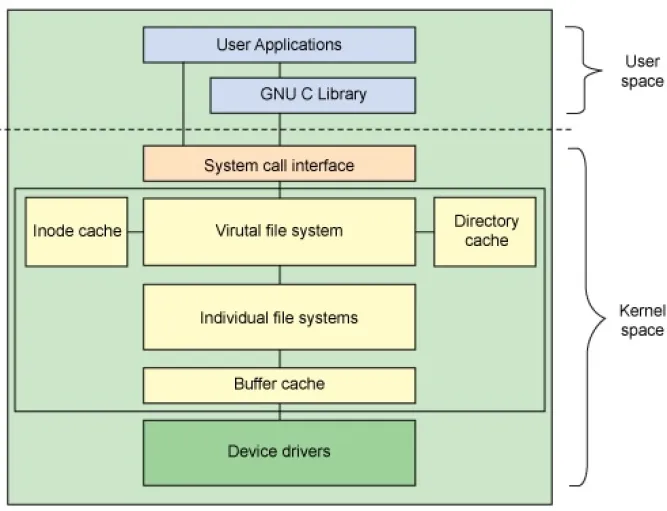
Below device drivers: hardware controllers - beyond this talk. They can also re-order writes and are mostly concerned with durability, i.e. a SSD controller will try to distribute the blocks he used to make sure they have a similar amount of write cycles.
How do syscalls work?
// Example: writing to a file // as documented in glibc: // ssize_t write( // int fd, // file descriptor // const void buf[], // data // size_t count // size of data // ); write(1, "Hello world!\n", 12);
Compiled:
; use the `write` system call (1) movl rax, 1 ; write to stdout (1) - 1st arg movl rbx, 1 ; use string "Hello World" - 2nd arg ; (0x1234 is the addr of the "Hello World!\0") movl rcx, 0x1234 ; write 12 characters - 3rd arg movl rdx, 12 ; make system call via special instruction syscall ; The return code is now in the RAX register.
Disclaimer: The 'syscall' instruction is not the only instruction and kind of deprecated in favor of another one. But it's similar enough and better to explain.
All available syscalls and their ids are here: https://filippo.io/linux-syscall-table/
Only method of userspace to talk to kernel. How to call is ISA specific.
The syscall instruction performs a context switch: This means the current state of the process (i.e. the state of all registers in the CPU) is saved away, so it can be restored later. Once done, the kernel sets the register to its needs, does whatever is required to serve the system call. When finished, the process state is restored and execution continues.
Context switches also happen when you're not calling any syscalls. Simply when the scheduler decide this process is done with execution.
Typical syscalls
- IO: read, write, close
- Files: stat, chmod, mkdir
- Memory: sbrk, mmap
- Processes: fork, kill, wait
- Network: listen, connect, epoll
- Mysterious: ioctl, chroot, mount
There is a syscall for every single thing that userspace cannot do without the kernel's help.
Luckily for us, glibc and Go provide us nice names and interfaces to make those system calls. They usually provide thin wrappers that also do some basic error checking. Watch out: fread is doing buffering in userspace!
Can anyone think of another syscall not in the list above? exit! chdir ... (There are about 300 of them)
Also, what things are no syscalls? Math, random numbers, cryptography, ... i.e. everything that can be done without any side effects or hardware.
Use the man, Luke!
$ man 2 read
Every man page in section refers to a system call.
Prayer of Syscalls
»Reduce the number of syscalls and thou shalt be blessed!«
Typical read I/O
char buf[1024]; int fd = open("/some/path", O_CREAT|O_RDONLY|O_TRUNC); size_t bytes_read = 0; while((bytes_read = read(fd, buf, sizeof(buf))) > 0) { /* do something with buf[:bytes_read] */ } close(fd);
There are two costs here: Copying the data and context switching.
Looks fairly straightforward and most of you might have written something like that already. Maybe even for sockets or other streams. BUT here's the thing: every read needs one syscall and all bytes from the file are copied to a userspace-supplied buffer. This model is flexible, but costs performance. With mmap() and io_uring we will see options that can, sometimes, work with zero copies.
Sidenote: Always be nice and close your file descriptors. That has two reasons:
- You are only allowed a certain maximum of file descriptors per process. (check with ulimit -a for soft limits and ulimit -aH for hard limits)
- If you write something to a file close will also flush file contents that are not written to disk yet.
Typical write I/O
char buf[1024]; size_t bytes_in_buf = 0; int fd = open("/some/path", O_CREAT|O_WRONLY|O_TRUNC); do { /* fill buf somehow with data you'd like to write, * set bytes_in_buf accordingly. */ } while(write(fd, buf, bytes_in_buf) >= 0) fsync(fd); close(fd);
Q1: Does this mean that the data is available to read() when write() returned? Q2: Is the data saved on disk after write() returns?
- A1: Mostly. There might be exotic edge cases with non-POSIX filesystems,
but you should mostly be able to assume this.
- A2: No. You should call fsync() to ensure that and even than, it is
sadly not guaranteed depending on the storage driver and hardware. (Kernel has to rely on the hardware to acknowledge received data)
---
There is a bug here though:
write() returns the number of written bytes. It might be less than bytes_in_buf and this is not counted as an error. The write call might have simply been interrupted and we expect that it is called another time with the remaining data. This only happens if your program uses POSIX signals that were not registed with the SA_RESTART flag (see man 7 signal). Since it's default, it's mostly not an issue in C.
Go hides this edgecase for you in normal likes fd.Write() or io.ReadAll(). However, the Go runtime uses plenty of signals and if you use the syscalls package for some reason, then you might be hit by this kind of bug. This does not affect only write() but also read() and many other syscalls.
Also please note: There is some error handling missing here.
Sidenote: APIs are important
// Don't: No pre-allocation possible func ReadEntry() ([]byte, error) { // allocate buffer, fill and return it. }
// Better: buf can be pre-allocated. func ReadEntry(buf []byte) error { // use buf, append to it. }
// Do: Open the reader only once to // reduce number of syscalls func ReadEntry(r io.Reader, buf []byte) error { // use buf, append to it. }
This is a reminder to the last session. Many Read()-like functions get passed a buffer in, instead of allocating one. This is good practice, as it allows calling ReadEntry() in a loop and re-using a buffer during that. Even better is of course no copying the data at all, but that's a different story.
»Buffered« I/O
- Almost all I/O is buffered, but some is double buffered.
- fread(): Does buffering in userspace; calls read().
- bufio.Reader: Same thing in Go.
Usecases:
- You need to read byte by byte.
- You need to "unread" some bytes frequently.
- You need to read easily line by line.
- You have logic that does small reads.
Otherwise: Prefer the simpler version.
Userspace buffered functions. No real advantage, but limiting and confusing API. Has some extra features like printf-style formatting. Since it imposes another copy from its internal buffer to your buffer and since it uses dynamic allocation for the FILE structure I tend to avoid it.
In Go the normal read/write is using the syscall directly, bufio is roughly equivalent to f{read,write} etc. fsync() is a syscall, not part of that even though it starts with "f"
Syscalls are expensive
$ dd if=/dev/urandom of=./x bs=1M count=1024 $ dd if=x of=/dev/null bs=1b 4,07281 s, 264 MB/s $ dd if=x of=/dev/null bs=32b 0,255229 s, 4,2 GB/s $ dd if=x of=/dev/null bs=1024b 0,136717 s, 7,9 GB/s $ dd if=x of=/dev/null bs=32M 0,206027 s, 5,2 GB/s
Good buffer sizes: \(1k - 32k\)
Each syscall needs to store away the state of all registers in the CPU and restore it after it finished. This is called "context switch".
Many syscalls vs a few big ones.
Try to reduce the number of syscalls, but too big buffers hurt too.
Making syscalls visible
# (Unimportant output skipped) $ strace ls -l /tmp openat(AT_FDCWD, "/tmp", ...) = 4 getdents64(4, /* 47 entries */, 32768) = 2256 ... statx(AT_FDCWD, "/tmp/file", ...) = 0 getxattr("/tmp/file", ...) = -1 ENODATA ... write(1, "r-- 8 sahib /tmp/file", ...)
Insanely useful tool to debug hanging tools or tools that crash without a proper error message. Usually the last syscall they do gives a hint.
Important options:
-C: count syscalls and stats at the end.
-f: follow also subprocesses.
-e: Trace only specific syscalls.
Page cache
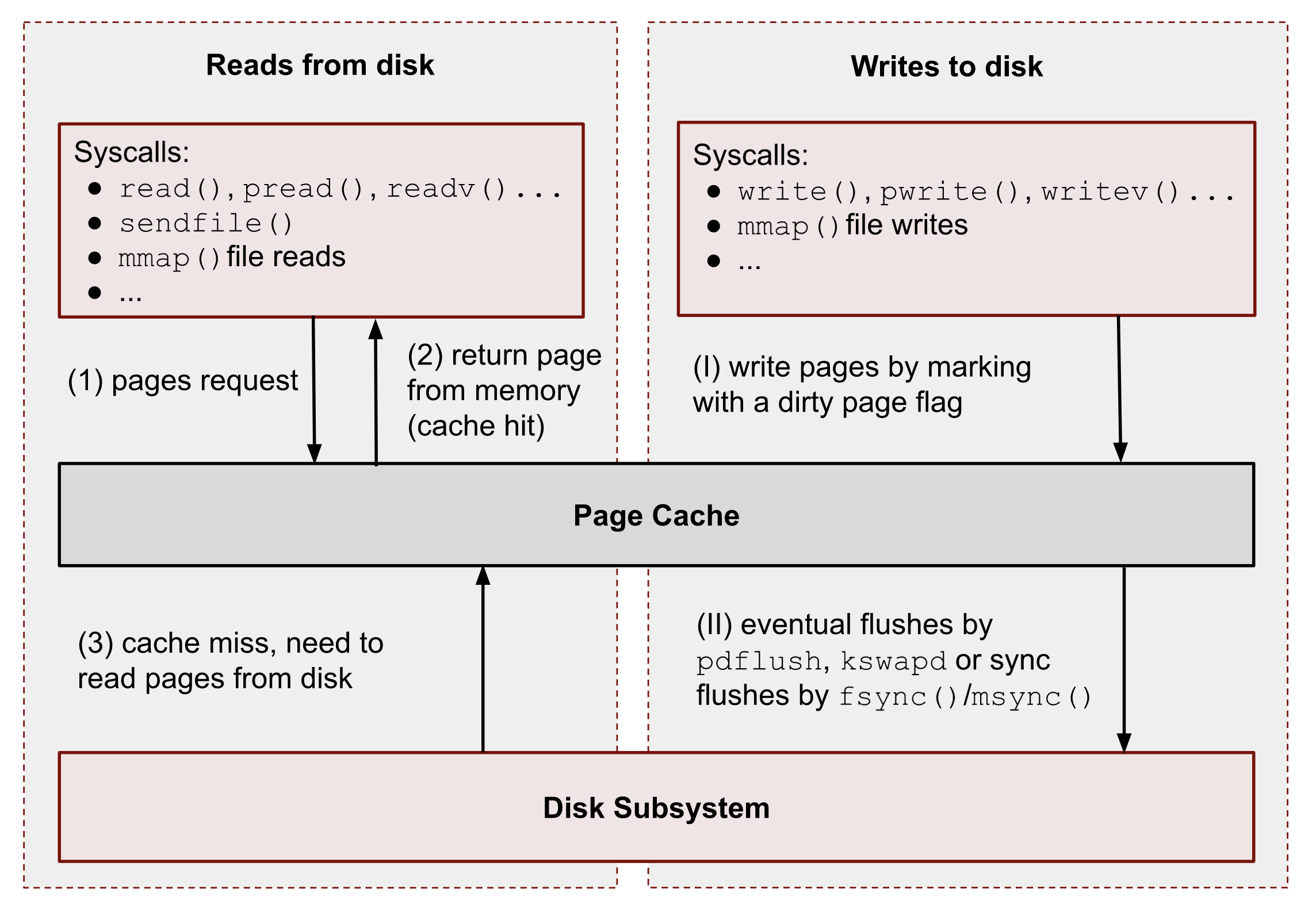
- All I/O access is cached using the page cache (dir + inode)
- Free pages are used to store recently accessed file contents.
- Performance impact can be huge.
- Writes are asynchronous, i.e. synced later
Good overview and more details here: https://biriukov.dev/docs/page-cache/2-essential-page-cache-theory/
Caveat: Writes are buffered!
# wait for ALL buffers to be flushed: $ sync # pending data is now safely stored.
// wait for specific file to be flushed: if(fsync(fd) < 0) { // error handling } // pending data is now safely stored.
That's why we have the sync command before the drop_cache command.
Clearing the cache
For I/O benchmarks always clear caches:
# 1: Clear page cache only. # 2: Clear inodes/direntries cache. # 3: Clear both. sync; echo 3 | sudo tee /proc/sys/vm/drop_caches
Example: code/io_cache
Alternative to fsync()
# Move is atomic! $ cp /src/bigfile /dst/bigfile.tmp $ mv /dst/bigfile.tmp /dst/bigfile
This only works obviously if you're not constantly updating the file, i.e. for files that are written just once.
Detour: Filesystems
Defines layout of files on disk:
- ext2/3/4: good, stable & fast choice.
- fat8/16/32: simple, but legacy; avoid
- NTFS: slow and only for compatibility.
- XFS: good with big files.
- btrfs: feature-rich, can do CoW & snapshots.
- ZFS: highly scalable and very complex.
- sshfs: remote access over FUSE
- ...
Do you know what filesystems you use? What filesystems you know?
Actual implementation of read/write/etc. for a single filesystem like FAT, ext4, btrfs. There are different ways to layout and maintain data on disk, depending on your use case.
Syscalls all work the same, but some filesystems have better performance regarding writes/reads/syncs or are more targeted at large files or many files.
Most differences are admin related (i.e. integrity, backups, snapshots etc.) and not so much performance related. But if you need things like snapshots and don't want external tools then btrfs of ZFS are incredibly fast.
Detour: Fragmentation
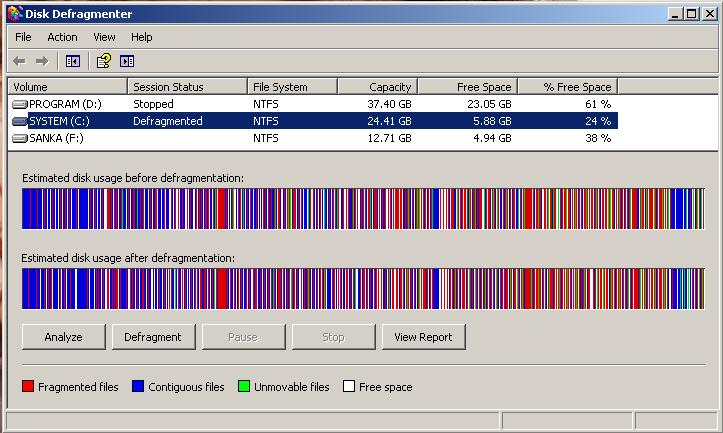
What OS do you think of when you hear "defragmentation"? Right, Windows. Why? Because NTFS used to suffer from it quite heavily. FAT suffered even more from this.
Fragmentation means that the content of a file is not stored as one continuous block, but in several blocks that might be scattered all over the place, possibly even out-of-order (Block B before Block A). With rotational disk this was in issue since the reading head had to jump all over the place to read a single file. This caused noticeable pauses.
Thing is: Linux filesystems rarely require defragmentation and if you are in need of defragmentation you are probably using an exotic enough setup that you know why.
Most Linux filesystems have strategies to actively, defragment files (i.e. bringing the parts of the file closer together) during writes to that file. In practice, it does not matter anymore today.
Detour: Tweaking
- Do not fill up your filesystem.
- Do not stack layers (overlayfs, luks, mdadm)
- Do not enable atime (Access time, noatime)
- Disable journaling if you like to live risky.
Performance is not linear. The fuller the FS is the, more it will be busy with background processes cleaning things up.
Stacking filesystems (like with using encryption) can slow things down. Often this without alternatives though. Only with RAID you have the option to choose hardware RAID.
Journaling filesystems like ext4 use something like a WAL. They write the metadata and/or data to a log before integrating it into the actual data structure (which is more complex and takes longer to commit). Data is written twice therefore with the advantage of being able to recover it on crash or power loss. Disabling it speeds things up at the risk of data loss (which might be okay on some servers).
Detour: FUSE
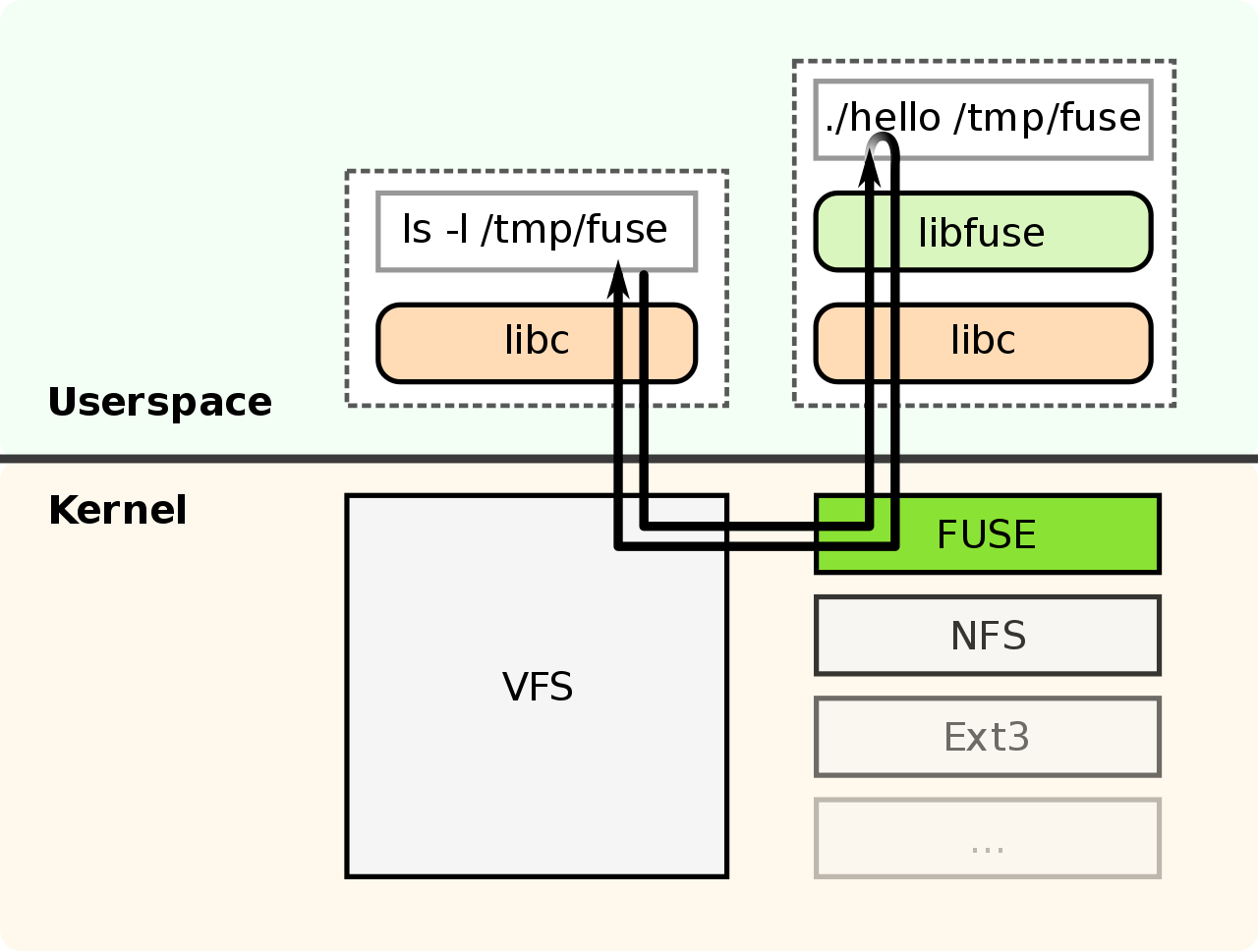
Examples of FUSE filesystems:
- s3fs
- sshfs
- ipfs / brig
FUSE gives you very decent performance, as most of the logic still runs in kernel space.
mmap()
// Handle files like arrays: int fd = open("/var/tmp/file1.db") char *map = mmap( NULL, // addr 1024 // map size PROT_READ|PROT_WRITE, // acess flags MAP_SHARED // private or shared fd, // file descriptor 0 // offset ); // copy string to file with offset map[20] = 'H'; map[21] = 'e'; map[22] = 'l'; map[23] = ';'; map[24] = 'W'; map[25] = 'o'; map[26] = 'r'; map[27] = 'd';
Example: code/mmap
Benchmarking IO is especially hard: Often you just benchmark the speed of your page cache for reading/writing. Always clear your cache and use fsync() during benchmarking extensivey!
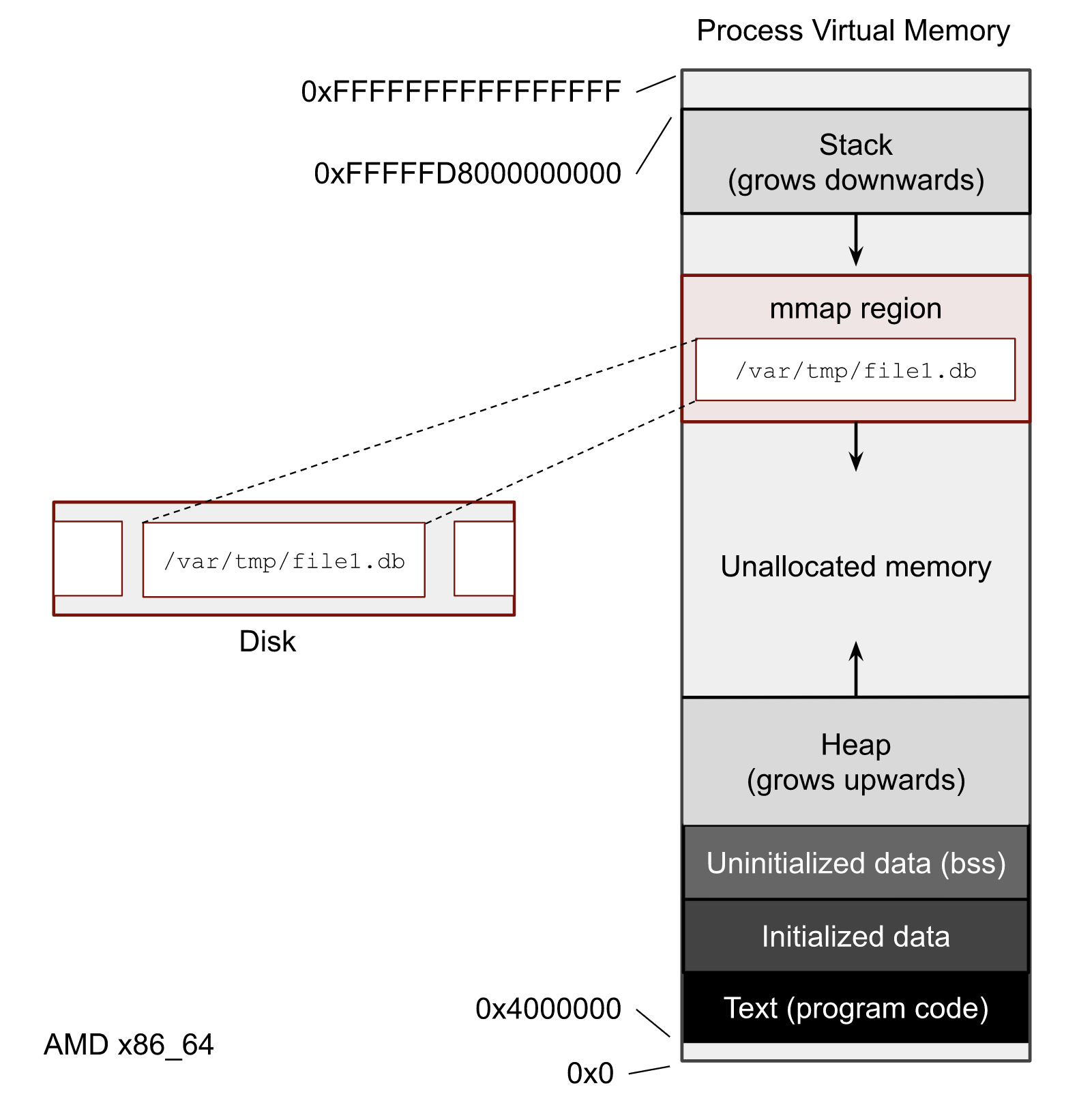
Maybe one of the most mysterious and powerful features we have on Linux.
Typical open/read/write/close APIs see files as streams. They are awkward to use if you need to jump around a lot in the file itself (like some datbases do).
With mmap() we can handle files as arrays and let the kernel manage reading/writing the required data from us magically on access. See m[17] above, it does not require reading the respective part of the file explicitly.
Good mmap use cases:
- Reading large files (+ telling the OS how to read)
- Jumping back and forth in big files.
- Sharing the file data with several processes in a very efficient way.
- Zero copy during reading! No buffering needed.
- Ease-of-use. No buffers, no file handles, just arrays.
Image source:
https://biriukov.dev/docs/page-cache/5-more-about-mmap-file-access/
mmap() controversy

- Some databases use mmap() (Influx, sqlite3, ...)
- Some people advise vehemently against it. 💩
- For good reasons, but it's complicated.
- Main argument: Not enough control & safety.
- For some usecases mmap() is fine for databases.
To sync or to async? 🤔
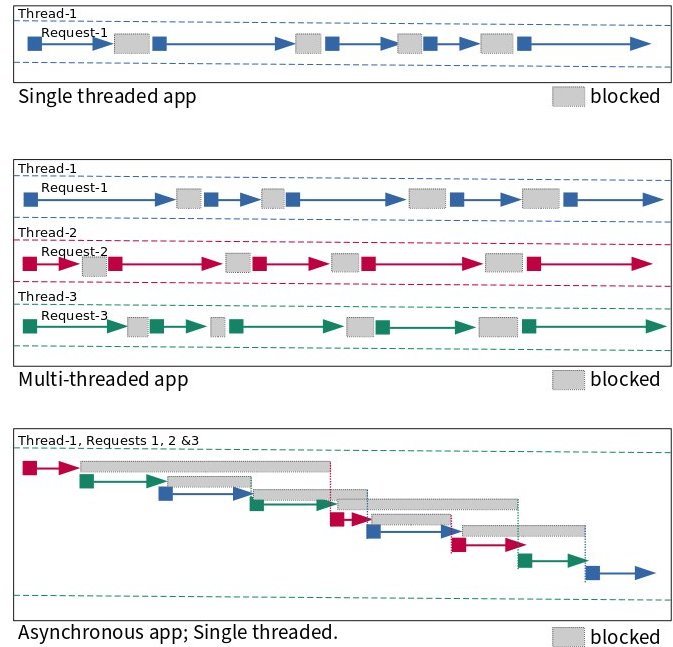
https://unixism.net/loti/async_intro.html
The image below can be achieved using special system calls like epoll(), poll() or select(): They "multiplex" between several files. Basically they work all the same: You given them a list of files and once invoked epoll() waits until one of the files are ready to be read from. This minimizes polling on userspace side and keeps the wait between I/O as low as possible.
This is however only possible for network I/O - normal files cannot be polled. Beyond the scope of this talk however.
io_uring
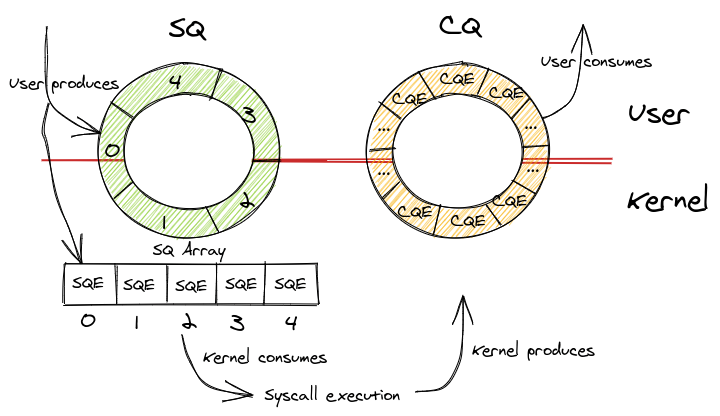
A technique to introduce polling mechanisms to files too and benefit from it.
SQ: Submission Queue: Commands like read file 123 at offset 42. CQ: Completion Queue: Here is the dat aof file 123 at offset 42.
Advantage: Does only need syscalls during the setup of the interface, but not during operation as the data transfer is done via a memory mapping that has been set up during the setup phase.
Myth: O_DIRECT 👎
// Skip the page cache; see `man 2 open` int fd = open("/some/file", O_DIRECT|O_RDONLY); // No use of the page cache here: char buf[1024]; read(fd, buf, sizeof(buf));
This flag can be passed to the open() call. It disables the page cache for this specific file handle.
Some people on the internet claim this would be faster, but this is 90% wrong. There are 2 main use cases where O_DIRECT has its use:
- Avoiding cache pollution: You know that you will not access the pages of a specific file again and not want the page cache to remember those files. This is a micro optimization and is probably not worth it. More or less the same effect can be safely achieved by fadvise() with FADV_DONTNEED.
- Implementing your own "page cache" in userspace. Many databases use this, since they have a better idea of what pages they need to cache and which should be re-read.
Myth: I/O scheduler 👎

Re-orders read and write requests for performance.
- none: Does no reordering.
- bfq: Complex, designed for desktops.
- mq-deadline, kyber: Simpler, good allround schedulers.
In the age of SSDs we can use dumber schedulers. In the age of HDDs schedulers were vital.
Myth: ionice 👎
# Default level is 4. Lower is higher. $ ionice -c 2 -n 0 <some-pid>
Well, you can probably guess what it does.
madvise() & fadvise()
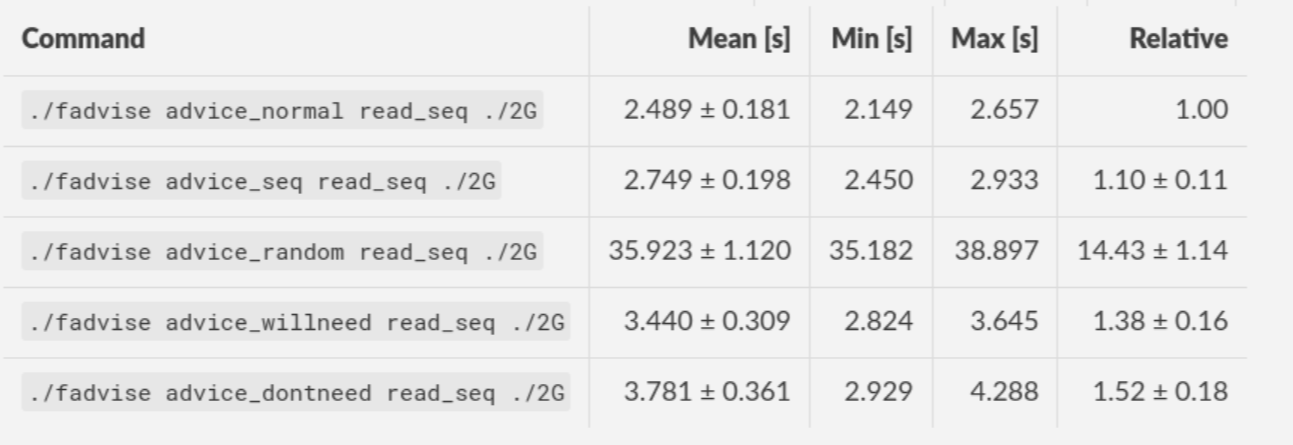
Example: code/fadvise
Example: code/madvise
fadvise() and madvise() can be used to give the page cache hints on what pages are going to be used next and in what order. This can make a big difference for complex use cases like rsync or tar, where the program knows that it needs to read a bunch of files in a certain order. In this case advises can be given to the kernel quite a bit before the program starts reading the file.
The linked examples try to simulate this by clearing the cache, giving a advise, waiting a bit and then reading the file in a specific order.
The examples also contain some noteable things:
- Reading random is much slower than reading forward.
- Reading backwards is the end boss and really much, much slower.
- hyperfine is a nice tool to automate little benchmarks like these.
- Complex orders (like heaps or tree traversal) cannot be requested.
- mmap does not suffer from the read order much and is much faster for this kind of no-copy-needed workload.
Why is cp faster?
package main import( "os" "io" ) // Very simple `cp` in Go: func main() { src, _ := os.Open(os.Args[1]) dst, _ := os.Create(os.Args[2]) io.Copy(dst, src) }
cp is not faster because it copies data faster, but because it avoids copies to user space by using specialized calls like:
- ioctl(5, BTRFS_IOC_CLONE or FICLONE, 4) = 0 (on btrfs)
- copy_file_range() - performs in-kernel copy, sometimes even using DMA
Find out using strace cp src dst. If no trick is possible it falls back to normal buffered read/write.
Find resource hogs 🐷
# Show programs with most throughput: $ iotop
Finding max throughput:
# Write: $ dd if=/dev/zero of=./file bs=32k count=10000 # Read: $ sync; echo 3 | sudo tee /proc/sys/vm/drop_caches && \ dd if=./file of=/dev/null bs=32k
NOTE: dd can be nicely used to benchmark the throughput of your disk! Just dd from /dev/zero for write perf and to /dev/null for read perf. But you have to use conv=fdatasync for both and clear the page cache (see below) in case.
Reduce number of copies
- Do not copy buffers too often (🤡)
- Use readv() to splice existing buffers to one.
- Use hardlinks if possible
- Use CoW reflinks if possible.
- sendfile() to copy files to Network.
- copy_file_range() to copy between files.
Not copying: using mmap, io_uring. If using read() file API then try to minimize copying in your application.
Good abstractions
type ReaderFrom interface { ReadFrom(r Reader) (n int64, err error) } type WriterTo interface { WriteTo(w Writer) (n int64, err error) }
You might have heard that abstractions are costly from a performance point of view and this partly true. Please do not take this an excuse for not adding any abstractions to your code in fear of performance hits.
Most bad rap of abstractions come from interfaces that are not general enough and cannot be extended when performance needs arise.
Example: io.Reader/io.Writer/io.Seeker are very general and hardly specific. From performance point of view they tend to introduce some extra allocations and also some extra copying that a more specialized implementation might get rid of if it would know how it's used.
For example, a io.Reader that has to read a compressed stream needs to read big chunks of compressed data since compression formats work block oriented. Even if the caller only needs a single byte, it still needs to decompress a whole block. If the API user needs another byte a few KB away, the reader might have to throw away the curent block and allocate space for a new one, while seeking in the underlying stream. This is costly.
Luckily, special cases can be optimized. What if the reader knows that the whole stream is read in one go? Like FADV_SEQUENTIAL basically. This is what WriteTo() is for. A io.Reader can implement this function to dump its complete content to the writer specified by w. The knowledge that no seeking is required allows the decompression reader to make some optimizations: i.e. use one big buffer, no need to re-allocate, parallelize reading/decompression and avoid seek calls.
So remember: Keep your abstractions general, check if there are specific patterns on how your API is called and offer optimizations for that.
I/O performance checklist: The sane part
- Avoid I/O. (🤡)
- Reduce the number of system calls.
- Use a sane buffer size with read()/write().
- Use append only writes if possible.
- Read files sequential, avoid seeking.
- Batch small writes, as they evict caches.
- Avoid creating too many small files.
- Make use of mmap() where applicable.
- Reduce copying (mmap, sendfile, splice).
- Compress data if you can spare the CPU cycles.
- In many cases I/O can be avoided by doing more things in memory or avoiding duplicate work.
- If you write/read a file several times, then do not open and close it every time.
- Anything between 1 and 32k is mostly fine. Exact size depends on your system and might vary a little. Benchmark to find out.
- Appending to a file is a heavily optimized flow in Linux. Benefit from this by designing your software accordingly.
- Reading a file backwards is much much slower than reading it sequentially in forward direction. This is also a heavily optimized case. Avoid excessive seeking, even for SSDs (syscall overhead + page cache has a harder time what you will read next)
- Small writes of even a single byte will mark a complete page from the page cache as dirty, i.e. it needs to be written. If done for many pages this will have an impact.
- Every file is stored with metadata and some overhead. Prefer to join small files to bigger ones by application logic.
- mmap() can be very useful, especially in seek-heavy applications. It can also be used to share the same file over several processes and it has a zero-copy overhead.
- Specialized calls can help to avoid copying data to userspace and do a lot of syscalls by shifting the work to the kernel. In general, try to avoid copying data in your application as much as possible.
- If you have really slow storage (i.e. SD-cards) but a fast CPU, then compressing data might be an option using a fast compression algorithm like lz4 or snappy.
I/O performance checklist: The deseperate part
- Use io_uring, if applicable.
- Buy faster/specialized hardware (RAID 0).
- Use no I/O scheduler (none).
- Tweak your filesystems settings (noatime).
- Use a different filesystem (tmpfs)
- Slightly crazy: fadvise() for cache warmup.
- Maybe crazy: use O_DIRECT
- Likely crazy: skip fsync()/msync())
- Do not fill up your FS/SSD fully.
- io_uring can offer huge benefits, especially when dealing with many files and parallel processing of them. It is definitely the most complex of the 3 APIs of read+write / mmap / io_uring and its usage most be warranted.
- Always a good option and often the cheapest one. RAID 0 can, in theory, speed up throughput almost indefinitely, although you'll hit limits with processing speeds quite fast.
- Mostly standard now. I/O schedulers were important in the age of HDDs. Today, it's best to skip scheduling (to avoid overhead) by using the none scheduler.
- If raw performance is needed, then you might tweak some filesystem settings, as seen before.
- Some filesystems are optimized for scaling and write workloads (XFS), while others are more optimized for desktop workloads (ext4). Choose wisely. The pros and cons go beyond the scope of this workshop. If you're happy with memory, you can of course tmpfs which is the fastest available FS - because it just does not use the disk.
- fadvise() can help in workloads that include a lot of files. The correct usage is rather tricky though.
- Some databases use direct access without page cache to implement their own buffer pools. Since they know better when to keep a page and when to read it from disk again.
- If you do not care for lost data, then do not use fsync() to ensure that data was written.
- Full SSDs (and filesystem) suffer more from write amplification and finding more free extents becomes increasingly challenging.
Fynn!
🏁