Intro
General intro and sideproject 🏠
Agenda
- Rant & Motivation
- Benchmarking Basics
- Complexity Theory
- Sideproject

What's that?
Who's that?

General idea:
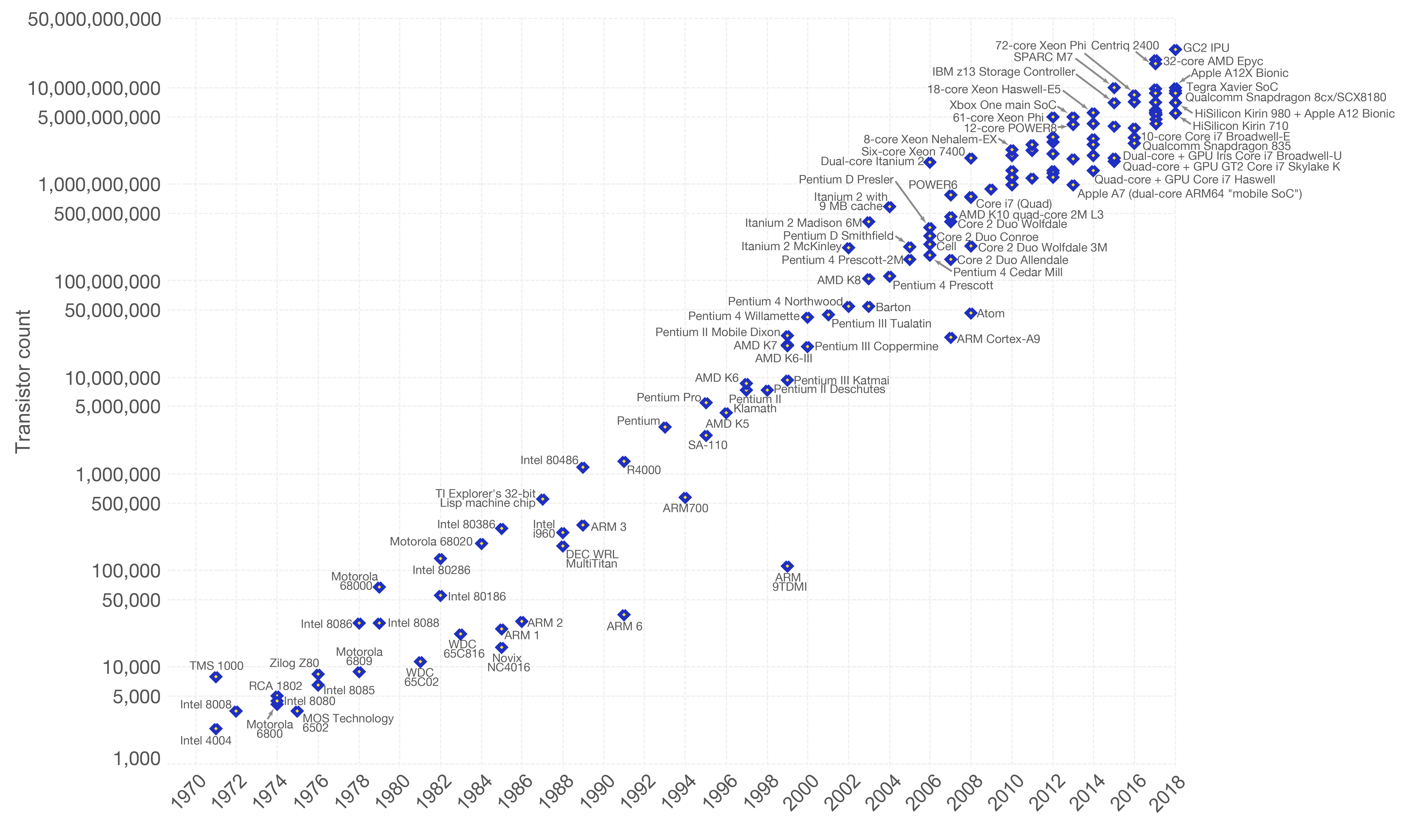
- Maybe you heard of Moore's law? Computing power doubles every two years
- Andy and Bill's law: What Andy Grove (Intel ex-CEO) produces in Hardware speed, Bill Gates takes away.
- Wirt's law: Software gets slower more rapdidly than hardware gets faster.
- Lemur's law: Software engineers get twice as incompentent every decade (only half ironic) - seriously, as an engineering discipline we should be ashamed of how bad we performed over the last decades. We introduced so many layers of bad software and hacks that we depend on that we can't change anymore. It's like building a complete city on sand. Part of this because we don't really do engineerings and focus so much on providing company value that many of us did not even learn how good, performance optimized is supposed to look like. The costs of software engineers is more expensive than hardware these days, but this is short sighted. Investing in quality long term benefits us all. I hope to change your perspective a bit in this talk. We all lost the connection to the machine our programs run on and while the things in this talk were somewhat common knowledge 20 years ago (at least parts of it) it became somehow obscure knowledge over time and universities just focused on disciplines like web development and data science where you're not supposed to have this knowledge. Because you know, numpy and pandas does it for you. Or the browser will just do the right thing.
Performance inflation

NOTE: Exaggerated of course and I kinda see myself also in that meme. Programming got much easier now, but also much ...broader. Much more languages, frameworks, concepts that a programmer is expected to know. Still: In earlier days, programming required a much more thorough approach with more experimentation and there was no StackOverflow, AI, Auto complete or even documentation. Throwing more hardware at the problem was also no choice. Knowledge today is much more superficial than it was before. Mostly, because deep understanding of how a computer works is simply not required to produce something that works.
The thing is: Not requiring this kind of knowledge is a blessing and a curse at the same time. A blessing for our productivity, but in general a curse for the software we produce:
- In the 90s we still squeezed every byte of memory out of game consoles and did both amazing and scary optimizations to get basic functionality.
- And last decade we invented things like Electron, a lazy-ass way to make applications "portable" by just starting a browser for every application
- The main motivation of this workshop was actually being annoyed by things like Electron and I wanted that you guys do not invent something like Electron.
- If you think Electron is a good idea, then please stop doing anything related to software engineering.
- Maybe try gardening, or do waterboarding in Guantanamo. Just do something less hurtful to mankind than Electron
- Seriously take some pride as software engineerings and try to leave a solid legacy to the next generation of engineers.
- Understanding how a computer works helps to not be like Bill Gates and just eat up hardware advancements with worse software.
Also, this is the only meme. I promise.
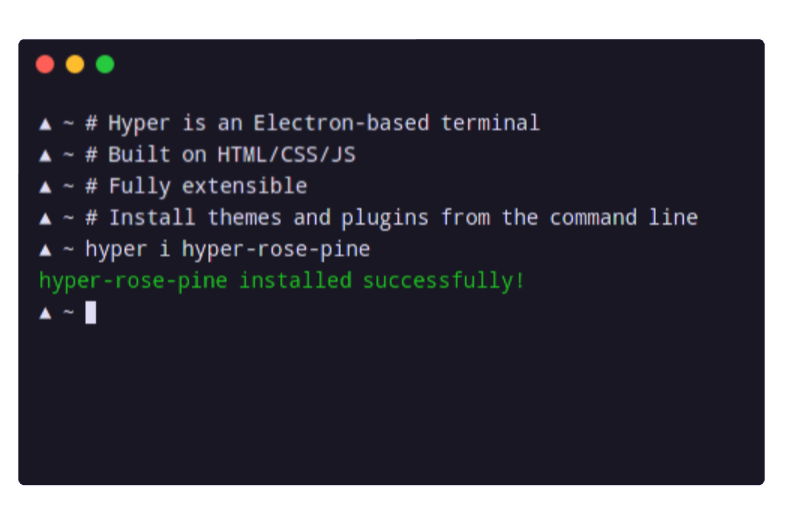
No joke: This electron based terminal took 700M (!) of residual memory. This is absolutely insane and should not have been released.
You could argue now: Well, we would care more about performance but in todays world we don't have time to time because we're agile and have to produce feature after feature. We care only once we get into troubles. This also leads to developers never learning about writing software that has to fulfill some performance criterias.
There is some truth about that. Product management usually is not that much aware of Performance if it's not a hard product requirement. But that's your job - you're supposed to measure performance and predict that it will be an issue. If you think it will be an issue, then you should fight for the time to fix it.
Anyways, in this workshop we will enter a fantasy world, where we have infinite amounts of time.
»Simple«
# Read in a line, print the line without whitespaces. # Most complexity here is hidden. import sys print(sys.stdin.readline().strip())
Complexity is often hidden, without you noticing, often with the intent to "make things simple".
Simple can mean different things. "simple" can mean "small cognitive load", i.e. programs that are simple to understand. "simple" can also mean "programs with few instructions and few abstractions"
The prior rules assume that we're able to understand what's going on in our program. After all we have to judge what gets executed ultimately. Turns out, in interpreted language this is very hard.
Interpreted -> compiled to byte code. sys.stdin.readline are two dict lookups. memory allocations file I/O from stdin to stdout calling a c function (strip) several syscalls unicode conversion!
Inside Python 🐍
static PyObject * strip(PyObject *self, PyObject *args) { char *s = NULL; if (!PyArg_ParseTuple(args, "s", &s)) { return NULL; } /* ... actual "strip" logic here ... */ return PyUnicode_FromString(s); }
All functions eventuall call functions implemented in C:
And that happens for every function call in Python. Very often. All those objects are allocated on the heap. Python is easy, but the price you pay for it is high. This might give you a first feeling on how much stuff happens in a simple program.
Printing to stdout and drawing something on the screen is insanely complex too and beyond this workshop.
This slides could be also a talk about "Why interpreted languages suck"
Most optimizations will not work with python. As a language it's really disconnected from the HW - every single statement will cause 100s or 1000s of assembly instructions. Also there are no almost no guarantees how big e.g. arrays or other data structures will be and how they are layout in memory. You have to rely on your interpreter (and I count Java's JIT as one!) to be fast on modern hardware - most are not and that's why there's so much C libraries in python, making the whole packaging system a bloody mess.
Side note: There are also declarative languages like SQL (as compared to imperative languages like C) that this workshop is not focusing on. Working on performance there is indirect, i.e. achieved by tricks.
Workshop contents
We try to answer these questions:
- Why is performance important?
- How does the machine we program on work?
- How do we notice this as developers?
- Are there ways to exploit this machine?
Remember: Work shop.
Disclaimer:
- We're working from low level to slightly higher level here. Don't expect tips like "use this data structure to make stuff incredibly fast". I'll won't go over all possible performance tips for your language (there are better lists on the internet). I also won't go over a lot of data structures - what I do show is to show you how to choose a data structure.
- The talk is loosely tied to the hardware: General intro, cpu, mem, io, parallel programming
- Most code examples will be in Go and C, as most ideads require a compiled language.
- Interpreted languages like Python/Typescript might take away a few concepts, but to be honest, your language is fucked up and will never achieve solid performance.
- For Python you can at least put performance criticals into C libraries, for the blistering cestpool that web technology is... well, I guess your only hope is Webassembly.
- If you are unsure how a specific concept translates to your language: just ask. I might have no idea, but often there is only a limited choice of design decisions language designers can make.
- In this talk you will learn why people invent things Webassembly - even though it's kinda sad.
My main goal is though to give you a "table of contents" of most things related to performance. The whole thing is at least one semester of contents. We don't have enough time though, so we will jump a lot from topic to topic while barely scratching the surface. This should not matter too much though as long you just remember later "Ah, Lemur said something about this behavior, but I dont recall the details, let's Google" (or maybe even open those slides again). The hardest part of experience is that concepts exists. Applying them is often easier. If you manage to do that I will be fairly happy.
This also means that you don't need to worry if you don't understand something at first glance. Note it down or directly ask during the workshop, but try to follow th ecurrent slides instead of trying to understand every last detail.
What can you do with it?
go bench | μs/op | B/op | allocs/op | speedup |
|---|---|---|---|---|
sqlite3-Pop | 4.878 | 1.239.961 | 6.217 | 1x |
sqlite3-Push | 2.420 | 688.887 | 32.034 | 1x |
timeq-Pop | 35 | 232 | 4 | 136x |
timeq-Push | 61 | 98 | 3 | 39x |
OP = Push/Pop 2k Items with 40 Bytes each.
https://github.com/sahib/timeq
It may not look like it, but this was the slide I put the most work into.
I wrote a persistent priority queue in Go. It's kinda fast. At the end of the workshop you should be able to understand why it is fast and why it's designed that way. Maybe you can even improve it!
By the way, this doesn't mean that SQLite is bad. It's a general purpose database that was forced into being a priority queue. There are obviously some assumptions that allow better performance.
Was it worth it?
- Choosing SQLite is an absolutely sane decision.
- Building your own database probably not so much.
- Designing/testing a production-grade DB is hard.
- Handling edgecases & errors gracefully is even worse.
- It's 50x faster, but it took 50x the work.
- Still, you should know how, if you have to.
At time of writing, timeq has roughly 1.5k lines of code. The amount of testcode is about the same amount. However, SQLite has 173x times the amount of test code and is readily packaged.
What's not in here?
- An exhausting list of tips. You'd forget them.
- A full lecture on algorithm and data structures.
- A lecture you just have to listen to make it click.
- Language specific optimization techniques.
- Performance in distributed systems.
- Application specific performance tips (Networking, SQL, Marshalling, IPC ...)
Google: I mean that. After the workshop you know what to google for. Hopefully.
There are plenty free online courses and many books. I can't really recommend one, as my lecture in university is also already 10 years ago now.
Languages: includes C, Go, Python and a bit of Bash though. Most code examples are written with compiled languages in mind. Users of interpreted languages may find some things unintuitive.
Check that "interpreted" and "compiled" is a known distinction.
Help!
- This workshop is written in a markup language (.rst).
- Almost every slide has speaker notes.
- I tried to make them generally understandable.
- If you need more background, read them:
Experiments mandatory 🥼
You'll write your own cute database:
- You can group up or do it on our own.
- You can use your favourite language.
- You can always ask me outside or in the workshop about your progress and problems.
But do the database for yourself, not for me. Also, not every topic in the slides has to be present in your database. I'm only sharing general ideads here, not implementation tips. You don't have to remember all of them, but hopefully you will take away the core thoughts behind those ideads.
Also, please note that I'm not expert in everything myself. I do those workshops to educate myself on a certain topic. Also, I'm guilty of breaking most of the "tips" I give in this talk. That should not come as a surprise, as every rule is made to be broken. Most of the time for stupid reasons though.
This might serve as career tip though: If you want to deep dive into a certain topic, then prepare a presentation about it. If you're able to explain it to others, then you're probably kind of good in it.
So: this is also some kind of test for myself.
What is optimization?
Please define it in your words.
In computer science, optimization is the process of modifying a software system to make some aspect of it work more efficiently or use fewer resources. -- Wikipedia
The "fewer resources" is the more important bit. See yourself as tenant of resources like CPU, Mem, disk, network, dbs, ... that you share with other tenants of the same system. Be nice to other tenants, don't just make your own life pleasant.
When to optimize?
If performance requirements are not met and when doing so does not hurt other requirements.
Wait, there are such requirements?
Most of us do implicit requirements: Does it feel fast enough? So probably more often than you do now.
Other requirements: Maintenability and readability e.g. or correctness.
Questions to ask:
- On what kind of system the software will run on?
- How many requests will there be in parallel?
- What kind of latency is the user willing to accept? (Games, Websites, ATMs, ...)
- How much scaling is expected in the next time?
- How long can we do without? Do we need it now?
- Will my technology choice be a bottleneck? (Python, React, Electron, ...)
- Does EdgeCaseX need to perform well?
- Are the optimizations worth the risk/effort?
- ...
It's your job to figure out the performance requirements. Your PM will likely not be technical enough to set realisitc goals, so you need to discuss with him what kind of use cases you have and what kind of performance is acceptable for them (the latter is your part) Figure out possible edge cases together (i.e. pathological use cases bringing down your requirement) The engineer is the driver of the conversation, as he know's where the problems are.
Do some basic calculations based on these questions and add X to your goals. Those are your requirements.
When not to optimize?
Programmers waste enormous amounts of time thinking about, or worrying about, the speed of noncritical parts of their programs, and these attempts at efficiency actually have a strong negative impact when debugging and maintenance are considered. We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil. Yet we should not pass up our opportunities in that critical 3%.

I used the full quote here, since it's often abbreviated as "premature optimization is the root of all evil" which has a totally different meaning.
Many programmers just asked "how fast can it be?" and not "how fast should it be?" That's a fine question for personal learning but not for an actual product where time is a resource.
If you don't have a problem you really should not do anything. It is difficult to define what a "problem" is.
Electron apparently defined that it's not a problem if low-memory devices can't use their framework.
Huh, premature?
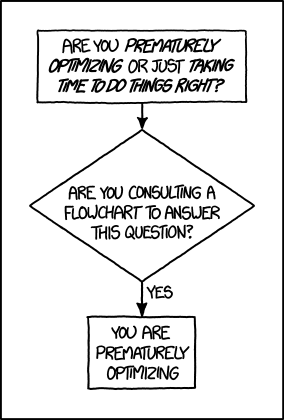
Reminder: It does not matter how fast you compute a wrong result.
Proof: There's a xkcd for everything.
The main point is: Take your time to do things the right away. Don't drop the pen when it worked for the first time and didn't feel slow, really take some to measure.
However, don't just blindly optimize things before you measured or optimize the small things after measuring.
Optimizations come at a price. It's usually more and harder code to maintain (and if not, why didn't you do it in the first place?) or they have some other disadavntages (an index in a database for example slows drown writes and needs space!). Is it worth the risk?
The mantra
- Make it correct.
- Make it beautiful.
- Make it fast.
In that order. Don't jump.
Often enough we do not even get to step 2 though. Sometimes not even step 1 :D Making things fast should always be a consideration. Software is not done once you are happy with the beautiful abstractions you found.
How do I measure?
In a reproducible environment.

Only ever compare apples with apples. Don't compare numbers between:
- Different machines.
- Different runs with different load on the same machine.
- Different inputs.
- Different implementations if they do not produce the same results.
Use benchmarks primarily to compare numbers of older benchmarks. And if you have to compare different implementations: Stay fair.
Profiling = Performance debugging. Benchmarking = Performance testing (i.e. ware optimizations still working?)
Example: Go
func BenchmarkFoo(b *testing.B) { possiblyExpensiveSetup() b.ResetTimer() for i := 0; i < b.N; i++ { functionUnderTest() } }
Example taken from here: https://www.p99conf.io/2023/08/16/how-to-write-accurate-benchmarks-in-go/
(it also has some good tips about many accidents that might happen, we'll see some of them later)
How to optimize?
- Do less work.
- Do the same work faster.
- Do the work at the same time.
- Do it in another order.
Examples:
- Use a different data structure (map vs btree)
- Do things like caching.
- threads, processes, coroutines.
- Do not wait for the longest part to finish to continue
Rules stolen from here: https://eblog.fly.dev/startfast.html
Measurement first
Requires a strong understanding of your program and experience.
- No way around measurements as first step.
- A certain level of experience helps.
- The model of your program in your head is different to what gets actually executed.
No short answer and no shortcuts to this. It will be a long journey and this is workshop will be only a step on the journey. Very many different languages, OS (Python, Go) and many different applications (SQL - 90%: just add an index) that cannot all be covered.
Example: If an application starts slow, then do you know what happens on startup? Maybe not - but it's important to take the right decisions.
Hot section
1 func process(b []byte) { 2 if(edgeCaseCondition) { 3 // ... 4 } 5 6 for i := 0; i < len(b); i++ { 7 for j := i; j < len(b); j++ { 8 b[i] = magicCalculation(b, i, j) 9 } 10 11 if i == len(b) - 1 { 12 for j := 0; j < len(b); j++ { 13 b[j] *= 2; 14 } 15 } 16 } 17 }
The Hot section is the path through your programs that is taken most often. This path defines the order in which you should optimize. If you optimize some edge case that is only taken 1% of the time, then the speedup of your optimization is also only worth 1%, because 99% of your program is still as slow as before.
How to find the path? Tools like pprof can find it, but also coverage tools or even debuggers can help you find them. Chances are that you the Hot section for your module anyways.
Other related terms are "Hot section" or "tight loop".
A related term is "slow path". This is often the path taken by a program that hits some edge case. Edge cases are often (purposefully) not optimized for, instead we generally optimize for the common "fast path".
A rule of thumb 👍
Go from big to small:
- Do the obvious implementation first.
- Check if your requirements are met.
- If not, find the biggest hot section.
- Optimize it and repeat from step 1.
- "obvious" depends a lot on experience. Example: Open a CSV file 10k times to extract a single row because you have a convenience function. Do not use this as excuse for bad software.
- If you don't have concrete functional/performance requirements, make some.
- We are incredible bad at guessing! Never ever skip this step!
- Never mix up this order.
Step 3 is the most difficult one. You should start measuring the full speed of your program then of one module and so on until you know what part consumes the most time/resources.
Theory: Complexity
- Algorithms/Structures can be divided in classes.
- General types are time and space complexity.
- Each divided in worst, best & average case.
- For datastructures specific operations are scored.
- Complexity classes are given in Big-O notation.
It's a bit like Pokemon for algorithms. "Merge sort, use worst case on quick sort!" "It's very effective!"
Good example (thanks Alex): https://sortvisualizer.com (compare quick sort and merge sort)
The general idea is to have a function that relates the number of elements given to an algorithm to the number of operations the algorithm has to do to produce a result.
Theory: Big-O Notation

https://www.bigocheatsheet.com
O(1) -> constant O(n) -> linear O(log n) -> logarithmic O(n * log n) -> sorting O(n ** x) -> polynomial O(x ** n) -> exponential O(n!) -> fucktorial (oops, typo)
Data structures and algorithms:
-> Some have better space / time complexity. -> Most have tradeoffs, only few are universally useful like arrays / hash tables -> Some are probalibisitic: i.e. they save you work or space at the expense of accuracy (bloom filters) -> Difference between O(log n) and O(1) is not important most of the time. (database developers might disagree here though)
For small n the difference doe snot mattern. It can be difficult to figure out what "n" is small.
Complexity exercises:
- Time complexity of Bubble Sort?
- Time complexity of Binary Search (worst & best)?
- Space complexity of Merge Sort versus Quick Sort?
- Removing an element from an Array vs a Linked List?
- Best/Worst case time complexity of Get/Set of Dicts?
- Space complexity of a Dict?
- O(n**2)
- O(log2 n) (both)
- O(n) vs O(1)
- O(n) vs O(1)
- O(1) and O(n) (but much more expensive than an array index)
- O(n)
Makes you wonder why you don't use hash maps all the time? Indeed they are a wonderful invention, but:
- get is still much more expensive than an array index.
- collisions can happen, making things inefficient.
- range queries and sorting are impossible.
- self balancing trees have O(log n) for get/set but are stable.
</Data structures lecture>

That's all. Go and remember a list of:
- Sorting algorithms (+ external sorting)
- Common & some specialized data structures.
- Typical algorithms like binary search.
- How much space common types use.
- Levenshtein, Graphs, Backtracking, ...
- ...whatever is of interest to you.
Data structures and algorithms is something you gonna have to learn yourself. Would totally go over the scope of this workshop and does not work as frontal lecture.
Do not ignore primitive algorithms like bubble sort. Remember: Fancy algorithms are slow when n is small, and n is usually small.
Performance metrics
Automated tests that assert the performance requirements of a piece of code by computing performance metrics and...
- ...either plot them for human consumption.
- ...compare against old versions.
- ...compare against constant thresholds.
Collect possible performance metrics (unit in parans):
- Execution time (time, cpu cycles)
- Latency (time)
- Throughput (IO, bytes/sec)
- Memory (allocations, peak, total bytes)
NOTE: Execution is heavily tied to hardware.
For CI/CD tools you can use something like this:
https://github.com/dandavison/chronologer
In an ideal world, performance requirements are tested just like normal functional requirements.
Challenges:
- Different machines that benchmarks run on.
- Only comparison between releases makes sense.
Makes sense only for big projects. Many projects have their own set of scripts to do this. I'm not aware of a standard solution.
Profiling
# Just the total time is already helpful. $ time <some-command> # Better: With statistics. $ hyperfine <some-command>
Profiling is usually used for finding a bottleneck. Basically a throw away benchmark, like a non-automated, manual test.
So most of the time the terms can be used interchangeably.
- Run several times.
- If the variance is not big, take the maximum.
- If the variance is rather large, use min...max.
Sideproject
What I cannot create, I do not understand.
Words don't cut it. To understand something you have to lay your hands on something and start exploring. Workshop is about tacit knowledge, you have to connect the little dots on my slides by working on this small slide project. I can only show you things, not understand and learn it for you.
tacit = unausgeprochen
I will share a sort of reference implementation some time after the workshop. There is no one right solution, but I will try to keep my solution well understandable and documented.
Memory only #1
type KV map[string][]byte func (kv *KV) Get(key string) []byte { return kv[key] } func (kv *KV) Set(key string, val []byte) { return kv[key] = val }
Memory only #2
func (kv *KV) sync() { var b bytes.Buffer for k, v := range kv { b.WriteString(fmt.Sprintf("%s=%s\n", k, v)) } return ioutil.WriteFile("/blah", b.Bytes(), 0644) } func load() *KV { data, err := ioutil.ReadFile("/blah") // ... parse file and assign to map ... return kv }
Obvious issue: It's all in the memory. If you need more entries than you have RAM you're in for a bad time.
You could use a big in-memory hash table and sync that to disk sometimes.
When do you call sync()? After every write? Inefficient. Less often? Then you will suffer data loss on power loss or crash.
Sounds impractical, but surprise: Redis actually works this way. They do not use a hash map internally though, but a tree structure as index. Oh, and they perform most work in a single thread. Still fast, but you have to consider its drawbacks.
Technical detail: Redis relies on the OS' paging mechanism, assuming that not every key in the database is used all the time. This allows to allocate a lot of memory, but to let the OS do the heavy lifting in the background to actually use a small portion of it only. This will be covered more in the memory chapter under "virtual memory".
Append only
init() { touch ./db } set() { printf "%s=%s\n" "$1" "$2" >> ./db } get() { grep "^$1=" ./db | tail -1 | cut -d= -f2- }
Simple append only write, get() reads only the last value. Every update of an existing key writes it again.
Terribly slow because get needs to scan the whole db, but very easy to implement and set is pretty fast. If you hardly ever call get then this might be a viable solution.
Indexed
type KV map[string]int64 func (kv *KV) Set(key string, val []byte) { // 1. Build entry with key and value. // 2. Append entry to end of db file. // 3. Update key-value index with offset. } func (kv *KV) Get(key string) []byte { // 1. Get offset & seek to it. // 2. Read value from db file at offset. }
This is actually already quite nice and I would be happy if you guys can implement it like that already.
This approach is called "log structured", because values are handled like a stream of logs, just timestamped (or offset stamped) data.
We can handle any number of values as long as we do not run out of memory. If we throw in a little caching, we could probably get decent performance. This would also be a decent usage for something called mmap which we will look into later in this series.
When loading the db file, we can reconstruct the index map easily.
Problems:
- There will be many duplicates if we update the same keys over and over.
- The database file will grow without bound. Might turn out problematic.
- There may only be one writer at a point (race condition between size of db and actual write).
Segmented

Solution:
- If the db file gets too big (> 32M), start a new one.
- Old one gets compacted in background (i.e. duplicates get removed)
- Index structure remembers what file we need to read.
The compaction step can be easily done in the background.
Open issues:
- We still need to have all keys in memory.
- Range queries are kinda impossible.
- We can't delete stuff.
TODO(FEEDBACK): Insert another step here to explain that we can replace the map ("memory segment") with a btree. Also explain roughly what a btree is.
Deletion

When we want to delete something, we just write a special value that denotes that this key was deleted. If a tombstone is the last value then the key is gone. Compaction can use it to clean up old traces of that value.
At this point we already build a key value store that is used out there: Bitcask.
Range queries

Change approach quite a bit:
- Keep a batch of key-value pairs in memory, but sorted by key.
- If batch gets too big, then swap to disk.
- Keep every 100th key in the offset index.
- If key not in index, go to file and scan the range.
This technique is called a Log-Structured-Merge tree (LSM).
"tree" because usually a tree is used instead of a hash table for easy handling, but this is not strictly necessary and the main point of the concept.
Since the index can be "sparse" (not all keys need to be stored), we have very fine grained control over memory usage. Worst thing is a bit of extra scanning in the file.
Open problems:
- Get on non-existing keys.
- Crash safety
WAL 🐋

What if a crash occurs before things get written to disk?
We have to use a WAL like above! On a crash we can reconstruct the memory index from it. Postgres and many other databases make use of this technique too.
Fynn!
🏁
I left quite some details out, but that's something you should be able to figure out.